|
Организация поиска и использование представленной в работе модели,
метода и алгоритмов зависит, прежде всего, от конкретных целей и задач,
решаемых реальной поисковой системой и особенностей ее архитектуры. Разработка
такой системы выходит за рамки диссертационной работы, и вопросы реализации тех
или иных аспектов поиска в рамках предлагаемого подхода остаются предметом
отдельного обсуждения. Однако некоторые наиболее общие задачи, характерные для
большинства поисковых систем, решаемые в рамках данного подхода применительно к
поиску документов по образцу, заслуживают внимания.
3.1.1. Тематическая классификация
Существует как минимум два варианта тематической классификации:
- для одного текста;
- для нескольких текстов.
И первый, и второй вариант предполагают выделение тематики на
основе структуры M(I, R). Подробно данный метод рассмотрен в параграфе 2.2.
Отличие второго варианта от первого в том, что тематическая
классификация и последующее вычисление тематической близости выполняется по
отношению к множеству текстов, объединенных общей тематикой.
Это множество неизбежно появляется по ходу поиска документов
на некоторую заданную тему. Человек, осуществляющий поиск, находит документы, в
той или иной мере удовлетворяющие его ожиданиям. При этом появляется
возможность организовать последующий поиск на основе нескольких, уже найденных
к этому моменту, документов. Реализуется это простой конкатенацией текстовых
фрагментов, т.е. один текст добавляется к другому, информационный поток в этом
случае описывает уже не один, а несколько текстов. Последующее выделение тематики
осуществляется на основе анализа такого обобщенного текста.
Принятие решения о том, какие тексты следует объединять для
организации последующего поиска, может осуществляться как самим человеком, так
и системой, например, в зависимости от вычисленных к этому моменту величин
тематической близости для множества проанализированных текстов (найденных
документов).
Кроме того, возможен вариант расширения тематики на основе
уточнения множества ключевых слов самим человеком.
Уточнение тематики может осуществляться человеком
произвольно, а может на основе контекстного анализа обобщенной информационной
структуры (обобщенного множества текстов). Преимущество контекстного анализа по
некоторому заданному набору ключевых слов для обобщенной информационной структуры
в том, что обобщенное множество текстов формирует единое понятийное поле.
Обобщенное множество текстов позволяет организовать всю
терминологическую базу, используемую в найденных документах, в связанную
структуру. И эту структуру можно использовать для дополнения произвольно
заданного набора ключевых слов.
3.1.2. Поиск
Поиск можно выполнять с помощью стандартных, отработанных
методов, реализуемых в настоящее время поисковыми системами. В частности, это
вариант векторной модели поиска или взвешенной булевой. Такой вариант поиска
предполагает формирование поискового запроса, состоящего из множества ключевых
слов. Это множество получается с помощью приведенного в работе метода частотно-контекстной
классификации. На его основе формируется поисковый запрос, который отрабатывает
поисковая система. Это может быть уже существующая поисковая система, с которой
интегрируется предложенный метод и алгоритмы, или уникальная реализация под
конкретную задачу.
По результату поиска получается множество документов. Используя
алгоритм вычисления степени тематической принадлежности текста к образцу, эти
документы анализируются, вычисляется их тематическая близость по отношению к
документу образцу, и затем они ранжируются по величине близости.
Кроме того, как было уже сказано выше, возможен вариант
поиска на основе обобщенного множества тематически близких документов.
3.1.3 Предварительная обработка текстов
Перед тем, как анализировать тексты в соответствии с представленной
в работе моделью необходимо выполнить их предварительную обработку.
Предварительная обработка текстов предполагает лексический и
морфологический анализ, а также исключение часто используемых слов (союзов, местоимений
и т.д.).
Рассмотрим подробнее этапы предварительной обработки текста:
1. Лексический анализ.
Заключается в разборе текста на отдельные абзацы,
предложения, слова, определении национального языка изложения.
На этом этапе выделяются отдельные слова из текста.
2. Исключение часто используемых слов.
В любом тексте существует большое количество слов,
используемых в качестве союзов, предлогов, местоимений и т.д., так называемые "стоп-слова",
("stop-words"). Такие слова
традиционно исключаются поисковыми системами при анализе документов.
Как правило, эти слова не определяют тематику текста, но при
этом являются частотно-значимыми. Это затрудняет выделение тематики на основе
анализа статистики слов. Такие слова необходимо исключать из текста.
Данная процедура выполняется на основе предварительно
составленного списка наиболее часто встречающихся слов в документах – списока игнорируемых
слов.
3. Морфологический анализ.
Морфологический анализ сводится к автоматическому распознаванию частей речи каждого слова текста.
На этом этапе слова приводятся к базовой форме.
Например, слова: компьютеры, компьютером, компьютера, компьютеру и т.д., заменяются на слово компьютер.
После предварительной подготовки текста, выполняется его обработка и тематический анализ по приведенным
ранее модели, методу и алгоритмам.
Разработанная выше модель структурного представления текста,
а также метод и алгоритмы тематического анализа реализованы в программном
исполнении в виде объектно-ориентированной библиотеки классов на C#.
Объектно-ориентированная реализация библиотеки на основе
языкового стандарта С++ (C# по своим языковым
конструкциям очень близок к С++), является востребованной и приемлемой в
современных условиях разработки программного обеспечения [31]. Использование
конкретного языка C# для этих целей было обусловлено
удобством использования памяти (автоматическое освобождение неиспользуемой
памяти – "сборка мусора"), а также объектной ориентацией данного языка.
Библиотека включает в себя следующие основные классы:
InfoAnalyzer - основной класс, отвечающий за обработку информационной структуры;
InfoElement - класс, отвечающий за представление и хранение информационных элементов;
InfoConverter - класс, преобразующий текст в набор связанных информационных элементов
(формирование информационной структуры);
InfoDocument - класс для загрузки документов различных форматов и преобразования их в текст;
InfoSearcher - класс, отвечающий за контекстный анализ;
InfoSettings - класс, отвечающий за настройки, в том числе за организацию списка игнорируемых слов;
Morpho - класс, отвечающий за морфологический анализ (приведение слов к базовой форме).
Общая структура библиотеки приведена на рис. 3.1.

Рис. 3.1. Библиотека классов
Взаимодействие этих классов, а также ряда вспомогательных,
позволяет преобразовывать текст в информационную структуру и затем
анализировать ее с помощью представленного в работе метода и алгоритмов
тематического анализа. Отдельные ее фрагменты, описывающие конкретную реализацию
того или иного метода и алгоритма, приводятся далее. Каждому основному классу
соответствует свой модуль.
Программный код, реализующий модель структурного
представления текста. Модуль InfoElement.
public class InOut
{
private InfoElement inIE;
private InfoElement outIE;
public InOut(InfoElement inIE_rq, InfoElement outIE_rq)
{
inIE = inIE_rq;
outIE = outIE_rq;
}
public InfoElement InIE
{
get {return inIE;}
}
public InfoElement OutIE
{
get {return outIE;}
}
}
public class InfoElement
{
public SortedList InOut = new SortedList();
private string name;
public InfoElement(string name_rq)
{
name = name_rq;
}
public string Name
{
get {return name;}
}
public bool ContainsInOut(InOut in_out)
{
foreach (InOut v in InOut.Values)
{
if (v.InIE == in_out.InIE)
if (v.OutIE == in_out.OutIE) return true;
}
return false;
}
}
|
Класс InOut реализует хранение двух ссылок, на предшествующий и последующий информационный элемент,
относительно некоторого информационного элемента в потоке. Далее экземпляр
класса InOut будем называть парой In-Out (т.к. данный класс хранит входной и выходной информационный элемент).
Класс InfoElement –
базовый элемент формируемой информационной структуры. Коллекция SortedList (стандартный тип С#) реализует хранение
отсортированного списка пар – (Key, Value).
Key – уникальный идентификатор данной пары (по которому
происходит сортировка), при формировании информационной структуры этот
идентификатор инициализируется текущим индексом потока (порядковым номером
слова в тексте).
Value – хранимое значение, в данном
случае используется для хранения ссылки на экземпляр класса InOut,
т.е. экземпляр класса InfoElement организует
хранение списка экземпляров класса InOut.
Модуль InfoConverter.
public InfoConverter(string text, SortedList allIE, SortedList ignor, ref int index)
{
ArrayList al = ConvertToArray(text, ignor);
if (al.Count < 2) return;
InfoElement ie_prev = null;
InfoElement ie = CreateIE((string)al[0], allIE);
InfoElement ie_next = CreateIE((string)al[1], allIE);
ie.InOut.Add(index++, new InOut(ie_prev, ie_next));
for (int i = 1; i < al.Count - 2; i++)
{
ie_prev = ie;
ie = ie_next;
ie_next = CreateIE((string)al[i + 1], allIE);
ie.InOut.Add(index++, new InOut(ie_prev, ie_next));
}
ie_next.InOut.Add(index++, new InOut(ie, null));
}
private InfoElement CreateIE(string name, SortedList allIE)
{
InfoElement ie = null;
if (!allIE.Contains(name))
{
ie = new InfoElement(name);
allIE.Add(name, ie);
}
else ie = (InfoElement)allIE[name];
return ie;
}
|
Из данного модуля приведены две главные процедуры.
InfoConverter – конструктор класса InfoConverter. Создание экземпляра данного класса реализует
преобразование текста в информационную структуру.
Входные параметры конструктора:
text – преобразовываемый текст.
allIE – указатель на список всех
информационных элементов существующих на текущий момент, если необходимо
достроить уже существующую информационную структуру (обобщенная информационная
структура), в этом списке необходимо задать уже существующие информационные
элементы.
ignor – указатель на список игнорируемых слов (союзы, местоимения и т.д.).
index – текущий индекс
информационного потока. Если идет моделирование нового информационного потока,
то индекс равен 0 (и список существующих информационных элементов пустой). По
окончанию формирования информационной структуры, в данной переменной
возвращается текущее значение индекса информационного потока, это значение
может потребоваться для достройки инф. структуры.
Далее по ходу текста процедуры отметим некоторые важные моменты.
ArrayList al = ConvertToArray(text, ignor); |
ConvrtToArray - вспомогательная процедура, конвертирует
текст (заданный строкой) в массив-список отдельных слов (ArrayList тип C#, подобен SortedList,
вместо сортировки - последовательная индексация элементов). Данная процедура
выделяет отдельные слова текста и организует их хранение в виде списка слов,
порядок слов в списке такой же, как и в тексте.
ignor – ссылка на список игнорируемых
слов.
Далее идет формирование информационных элементов и
информационной структуры.
InfoElement ie = CreateIE((string)al[0], allIE); |
Создание информационного элемента путем вызова процедуры CreateIE. В данном случае первым параметром этой процедуры
является первое слово в предварительно подготовленном массиве-списке, вторым -
список всех существующих к настоящему времени информационных элементов. Процедура
CreateIE создает информационный
элемент или возвращает указатель на существующий, если уже есть информационный
элемент с таким именем.
ie.InOut.Add(index++, new InOut(ie_prev, ie_next)); |
Добавить к списку пар In-Out, данного информационного элемента ie, новую пару In-Out – предшествующий ему
информационный элемент ie_prev и следующий за ним информационный элемент ie_next.
Последующий цикл реализует проход по всем словам текста и
формирование на их основе информационной структуры.
Модуль InfoAnalyzer.
public SortedList GetKey(int threshold, int range, int screen)
{
ArrayList key = GetPrimaryKey(threshold);
key = GetExpandPrimary(key, range, screen);
SortedList key_sl = ConvertToSortedList(key);
Reduction(key_sl);
return key_sl;
}
public ArrayList GetPrimaryKey(int threshold)
{
int max = GetMaxInOut();
int val = (int)((max / 100.0) * threshold);
ArrayList result = new ArrayList();
foreach (InfoElement ie in allIE.Values)
{
if (ie.InOut.Count >= val)
{
result.Add(new IE_Count(ie, ie.InOut.Count));
}
}
SortArrayList sort = new SortArrayList(result);
return result;
}
private int GetMaxInOut()
{
int max = 0;
foreach (InfoElement ie in allIE.Values)
{
if (max < ie.InOut.Count) max = ie.InOut.Count;
}
return max;
}
public ArrayList GetExpandPrimary(ArrayList primary, int range, int screen)
{
InfoSearcher search = new InfoSearcher();
ArrayList result = search.SearchContext(ConvertToSortedListSimple(primary), range, screen);
return result;
}
static public SortedList ConvertToSortedList(ArrayList al)
{
if (al == null) return null;
SortedList result = new SortedList();
foreach (IE_Count ie_count in al)
{
result.Add(ie_count.IE.Name, new IE_Value(ie_count.IE, ie_count.Count));
}
return result;
}
static public void Reduction(SortedList sl)
{
double sum = 0;
foreach (IE_Value ie_value in sl.Values) sum += ie_value.Value;
foreach (IE_Value ie_value in sl.Values)
{
double k = ie_value.Value / sum;
ie_value.Value = k;
}
}
public class IE_Count
{
public InfoElement IE;
public int Count;
public IE_Count(InfoElement ie, int count)
{
IE = ie;
Count = count;
}
}
public class IE_Value
{
public InfoElement IE;
public double Value;
public IE_Value(InfoElement ie, double val)
{
IE = ie;
Value = val;
}
}
|
Процедура GetKey возвращает список ключевых элементов.
Входные параметры:
threshold – порог в процентах, необходимый для определения первичного множества ключевых элементов;
range – окрестность, в пределах которой осуществляется контекстный анализ;
screen – параметр отсечки, используется для исключения из множества ключевых элементов тех элементов,
количество повторений которых меньше или равно screen.
Данная процедура осуществляет переадресацию вызова двум другим процедурам: GetPrimaryKey и
GetExpandPrimary, реализующим соответственно получение первичного множества ключевых элементов и
расширение этого множества контекстом.
Затем:
SortedList key_sl = ConvertToSortedList(key) – вспомогательная процедура конвертирования коллекции из
одного формата в другой;
Reduction(key_sl) – приведение к единице.
Порядок выполнения GetPrimaryKey.
int max = GetMaxInOut() – получить максимальное количество
пар In-Out (определить значение
d(M(I, R))max). GetMaxInOut
реализует это перебором всех информационных элементов и определением
максимального числа пар In-Out
для некоторого из них.
В классе InfoAnalyzer определен атрибут allIE – список всех информационных элементов.
public class InfoAnalyzer
{
private SortedList allIE = new SortedList();
...
|
Все перечисленные выше процедуры – методы класса InfoAnalyzer, которые имеет доступ к
переменной allIE – атрибуту класса InfoAnalyzer.
foreach (InfoElement ie in allIE.Values) – реализует перебор всех элементов коллекции
allIE (в данном случае сортированного списка), foreach – это один из циклов
реализованных в C#. При перебое переменной ie последовательно присваиваться ссылка на каждый информационный
элемент.
Результатом процедуры является список частотно-значимых информационных
элементов, упорядоченных по числу их повторений в тексте. SortArrayList –
вспомогательный класс, реализующий сортировку коллекции ArrayList,
элементами которой являются экземпляры класса IE_Count (использование SortedList –
встроенного типа C#, в данном конкретном случае, не совсем удобно).
Теперь перейдем к процедуре GetExpandPrimary, она переадресует вызов методу
SearchContext, класса InfoSearch. Данный метод реализует контекстный анализ и
дополнение первичного множества ключевых элементов. Рассмотрим его подробнее. Модуль
InfoSearch.
public ArrayList SearchContext(SortedList subject, int range, int screen)
{
if (subject == null) return null;
SortedList candidate = new SortedList();
foreach (InfoElement ie in subject.Values)
{
for (int i = 0; i < ie.InOut.Count; i++)
{
int startIndex = (int)ie.InOut.GetKey(i);
InfoElement ie_next = ie;
for (int index = startIndex; index < startIndex + range; index++)
{
InfoElement ie_v = ((InOut)ie_next.InOut[index]).OutIE;
if (ie_v == null) break;
int index_v = index + 1;
CandidateTest(ie_v, index_v, subject, candidate);
ie_next = ie_v;
}
InfoElement ie_prev = ie;
for (int index = startIndex; index > startIndex - range; index--)
{
InfoElement ie_v = ((InOut)ie_prev.InOut[index]).InIE;
if (ie_v == null) break;
int index_v = index - 1;
CandidateTest(ie_v, index_v, subject, candidate);
ie_prev = ie_v;
}
}
}
ArrayList result = new ArrayList();
for (int i = 0; i < candidate.Count; i++)
{
IE_Index ie_index = (IE_Index)candidate.GetByIndex(i);
if (ie_index.Index.Count >= screen)
result.Add(new IE_Count(ie_index.IE, ie_index.Index.Count));
}
for (int i = 0; i < subject.Count; i++)
{
InfoElement ie = (InfoElement)subject.GetByIndex(i);
result.Add(new IE_Count(ie, ie.InOut.Count));
}
SortArrayList sort = new SortArrayList(result);
return result;
}
private void CandidateTest(InfoElement ie, int index, SortedList subject, SortedList candidate)
{
if (subject.Contains(ie.Name)) return;
if (!candidate.Contains(ie.Name))
{
IE_Index ie_index = new IE_Index(ie);
ie_index.Index.Add(index, 0);
candidate.Add(ie.Name, ie_index);
}
else
{
IE_Index ie_index = ((IE_Index)candidate[ie.Name]);
if (!ie_index.Index.Contains(index))
ie_index.Index.Add(index, 0);
}
}
|
Входными параметрами процедуры являются:
subject - список ключевых элементов образующих
тематику текста, этот список соответствует первичному множеству ключевых
элементов;
range – окрестность в которой выполняется контекстный анализ;
screen – порог, который определяет
число повторений информационного элемента в процессе анализа контекста, для
включения в результирующий список (обычно эта величина 2, т.е. включать в
результирующий список все те элементы которые встречались 2 и более раза).
Для каждого информационного элемента ie, входящего в subject, выполняется
контекстный анализ, который заключается в следующем:
- Перебираются все пары In-Out, которые соответствуют прохождениям информационного потока через данный элемент:
for (int i = 0; i < ie.InOut.Count; i++).
- Определяется индекс пары:
int startIndex = (int)ie.InOut.GetKey(i). Используя этот индекс осуществляется проход вперед и
назад по информационному потоку:
for (int index = startIndex; index < startIndex + range; index++),
for (int index = startIndex; index > startIndex - range; index--).
В процессе прохода инициализируется переменная ie_v – текущий проверяемый инф.
элемент (этот элемент входит в окрестность ie).
- Выполняется проверка:
CandidateTest(ie_v, index_v, subject, candidate).
На вход этой процедуры передается текущий проверяемый инф.
элемент ie_v и его индекс в
потоке.
Эта процедура проверяет, существует ли текущий проверяемый
информационный элемент в списке "кандидатов". Если нет, то он добавляется, если
существует, то выполняется дополнительная проверка – "элемент с таким индексом
уже находили?" Ситуация повторного нахождения одного и того же информационного
с одним и тем же индексом в информационном потоке возможна в случае пересечения
окрестностей информационных элементов входящих в subject
(первичное множество ключевых элементов). Подсчитывать количество повторений в
этом случае нельзя, т.к. число повторений некоторого информационного элемента
входящего в окрестность может превысить число повторений информационного элемента
входящего в subject.
Вспомогательный класс IE_Index необходим как раз для реализации
такой проверки.
public class IE_Index
{
public InfoElement IE;
public SortedList Index = new SortedList();
public IE_Index(InfoElement ie)
{
IE = ie;
}
}
|
- В результирующий список копируются найденные информационные элементы из списка
candidate,
удовлетворяющие условию – число повторений больше или равно screen, также в
результирующий список копируются все информационные элементы, входящие в subject.
- Выполняется сортировка результирующего списка (сортировка по количеству их повторений).
Модуль InfoAnalyzer.
static public SortedList CalculateNearness(SortedList standard, SortedList verifiable,
int range, ref double total)
{
total = 0;
SortedList result = new SortedList();
for (int i = 0; i < standard.Count; i++)
{
string ie = (string)standard.GetKey(i);
if (verifiable.Contains(ie))
{
double k1 = ((IE_Value)standard.GetByIndex(i)).Value;
double k2 = ((IE_Value)verifiable[ie]).Value;
double w = Nearness(k1, k2);
SortedList subject = new SortedList();
InfoSearcher search = new InfoSearcher();
subject.Add(ie, ((IE_Value)standard.GetByIndex(i)).IE);
ArrayList environment1 = search.SearchContext(subject, range, 0);
SortedList environment1_sl = ConvertToSortedList(environment1);
subject.Clear();
subject.Add(ie, ((IE_Value)verifiable[ie]).IE);
ArrayList environment2 = search.SearchContext(subject, range, 0);
SortedList environment2_sl = ConvertToSortedList(environment2);
double context = CompareEnvironment(environment1_sl, environment2_sl);
w *= context;
result.Add(ie, w);
total += w;
}
else result.Add(ie, (double)0);
}
return result;
}
static private double Nearness(double standard, double verifiable)
{
double k_max = standard;
double k_min = verifiable;
if (standard < verifiable)
{
k_max = verifiable;
k_min = standard;
}
double w = (k_min / k_max) * standard;
return w;
}
private static double CompareEnvironment(SortedList environment1, SortedList environment2)
{
int intersection = 0;
foreach (string ie in environment1.Keys)
{
if (environment2.Contains(ie)) intersection++;
}
double result = (double)(intersection * 2) /
(double)(environment1.Count + environment2.Count);
return result;
}
|
Процедура CalculateNearness реализует вычисление тематической близости.
Входные параметры:
standard – список ключевых элементов текста образца, хранимые пары значений:
key типа string - имя информационного элемента и value типа
IE_Value;
verifiable – список ключевых элементов анализируемого на тематическую близость текста;
range – окрестность, в которой будет учитываться контекст.
Выходные параметры:
total – значение тематической близости;
список ключевых элементов (SortedList) с отдельно вычисленной тематической
близостью по каждому информационному элементу.
Порядок работы процедуры.
- Проход по всем информационным элементам
standard
for (int i = 0; i < standard.Count; i++),
string ie = (string)standard.GetKey(i).
- Проверка существования информационного элемента ie в списке
verifiable:
if (verifiable.Contains(ie))
- При наличии такого элемента в
verifiable - вычисление тематической близости для
данного информационного элемента.
double w = Nearness(k1, k2).
- Учет контекста.
ArrayList environment1 = search.SearchContext(subject, range, 0),
ArrayList environment2 = search.SearchContext(subject, range, 0).
И затем вызов процедуры CompareEnvironment, которая
возвращает коэффициент контекстной близости 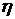 , учитывающий идентичность контекстов. Процедура , учитывающий идентичность контекстов. Процедура
CompareEnvironment реализует вычисление по формуле:

- Вычисление общей тематической близости:
total += w.
И формирование выходного списка ключевых элементов с
отдельно вычисленными значениями тематической близости по каждому из инф.
элементов: result.Add(ie, w). Формирование данного списка не обязательно, если
требуется получить только значение общей тематической близости по всему тексту.
При тестировании библиотеки, с помощью этого списка удобно контролировать
промежуточные расчеты.
public double FindParamSubject(string text_v1, string text_v2,
double expert_v1, double expert_v2,
ref int threshold, ref int range, ref double scale)
{
double[,] array_v1 = null;
CalculateNearnessParam(text_v1, ref array_v1);
double[,] array_v2 = null;
CalculateNearnessParam(text_v2, ref array_v2);
double diff = MinimizationDiff(expert_v1, expert_v2, array_v1, array_v2,
ref threshold, ref range, ref scale);
return diff;
}
public void CalculateNearnessParam(string textVerifiable, ref double[,] array)
{
InfoAnalyzer ia_verifiable = CreateAnalyzer(textVerifiable);
array = new double[param_range.Length, param_threshold.Length];
for (int k = 0; k < param_threshold.Length; k++)
{
int threshold = param_threshold[k];
for (int i = 0; i < param_range.Length; i++)
{
int range = param_range[i];
SortedList standard = null;
SortedList verifiable = null;
standard = GetKey(threshold, range, 1);
verifiable = ia_verifiable.GetKey(threshold, range, 1);
double nearness = 0;
CalculateNearness(standard, verifiable, range, ref nearness);
array[i, k] = nearness;
}
}
}
private InfoAnalyzer CreateAnalyzer(string text)
{
InfoAnalyzer ia = new InfoAnalyzer(ignor);
ia.Convert(text);
return ia;
}
public void Convert(string text)
{
InfoConverter converter = new InfoConverter(text, allIE, ignor, ref index);
index++;
}
public double MinimizationDiff(double expert_v1, double expert_v2,
double[,] array_v1, double[,] array_v2,
ref int threshold, ref int range, ref double scale)
{
int countT = param_threshold.Length;
int countR = param_range.Length;
double diff_min = double.MaxValue;
threshold = 0;
range = 0;
double calc_v1 = 0;
double calc_v2 = 0;
double diff_expert = expert_v2 / expert_v1;
for (int k = 0; k < countT; k++)
{
for (int i = 0; i < countR; i++)
{
double diff_calc = array_v2[i, k] / array_v1[i, k];
double diff = Math.Abs(diff_expert - diff_calc);
if (diff < diff_min)
{
diff_min = diff;
threshold = param_threshold[k];
range = param_range[i];
calc_v2 = array_v2[i, k];
calc_v1 = array_v1[i, k];
}
}
}
scale = ((expert_v1 / calc_v1) + (expert_v2 / calc_v2)) / 2.0;
return diff_min;
}
|
Процедура FindParamSubject реализует поиск параметров тематики (значений информационных
признаков тематики текста).
Входные параметры:
text_v1 – текст 1 оцененный экспертом на тематиче6скую близость по отношению к тексту образцу.
В качестве текста образца выступает уже сформированная к настоящему времени
информационная структура. Все перечисленные выше процедуры – методы класса InfoAnalyzer,
соответственно они имеют доступ к информационной структуре, связанной с данным классом, через атрибут
класса allIE (список всех инф. элементов).
text_v2 – текст 2 оцененный экспертном.
expert_v1 – оценка тематической близости текста 1 по отношению к тексту образцу.
expert_v2 – оценка тематической близости текста 2.
Выходные параметры:
threshold – порог в процентах, необходимый для выделения первичного множества ключевых элементов;
range – окрестность, необходимая для контекстного анализа;
scale – масштабирующий коэффициент.
Процедура FindParamSubject реализует
вызов процедуры CalculateNearnessParam для текста 1 и
2, эта процедура вычисляет массивы значений (для каждого из текстов)
тематической близости с различными комбинациями параметров использованных при
выделении тематики.
Комбинируются параметры на основе массивов заданных значений:
param_threshold и param_range.
Эти массивы определены как атрибуты класса InfoAnalyzer.
public class InfoAnalyzer
{
...
public int[] param_threshold = new int[] {90, 80, 70, 60, 50, 40, 30, 20, 10};
public int[] param_range = new int[] {0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12};
...
|
Результат работы процедуры CalculateNearnessParam
для двух текстов – массивы array_v1 и array_v2. Эти массивы используются
процедурой MinimizationDiff, которая осуществляет поиск
оптимальных параметров на основе ранее вычисленных значений тематической
близости (array_v1, array_v2). Поиск реализуется простым перебором.
В данной главе рассмотрены практические вопросы организации
поиска документов по образцу на основе предложенной в работе модели, метода и
алгоритмов, а также приведена их конкретная реализация в виде
объектно-ориентированного программного кода на языке C#.
Представленные фрагменты кода позволяют детальнее
рассмотреть практические аспекты реализации и использования предложенных в
работе результатов.
|

 материалы
материалы