|
Необходимо провести экспериментальное исследование
адекватности и корректности представленного в работе метода и алгоритмов
тематического анализа. Для каждого из них существуют свои особенности и условия,
определяющие ход проведения эксперимента. Рассмотрим их подробнее.
1) Метод частотно-контекстной классификации тематики текста.
Само понятие тематики заведомо предполагает субъективный
характер оценки получаемых результатов. Только человек может оценить, насколько
тематика (машинное представление темы текста) адекватна теме текста (субъективному
представлению пользователя о содержании текста). Также необходимо учитывать
сильную зависимость от текста, адекватность и корректность выделения тематики
можно оценить только по реальному тексту. Все это обуславливает характер и
особенности экспериментальных исследований метода частотно-контекстной
классификации тематики текста.
Единственно возможный способ прямой оценки результатов использования
метода – это приведение примеров выделения тематики некоторых текстов с
различными параметрами, используемыми при выделении тематики.
Кроме этого существует возможность косвенной оценки метода частотно-контекстной
классификации на основе экспериментальных исследований алгоритма вычисления
степени тематической принадлежности текста к образцу. Очевидно, что
корректность вычисления тематической близости зависит от корректности выделения
тематики. Рассмотрим один из вариантов оценки результатов вычисления тематической
близости.
2) Алгоритм вычисления степени тематической принадлежности
текста к образцу.
Корректность и адекватность данного алгоритма, а вместе с
ним метода частотно-контекстной классификации тематики текста можно оценить по
сходимости следующего условия:
 , , |
(4.1) |
w3
стремится к 1, тогда и только тогда, когда модуль разницы w1
и w2 стремится к 0, где: w1,
w2, w3 – тематическая
близость между текстами T1,
T2, T3.
На рис. 4.1 обозначено, каким парам текстов соответствует каждое
w.

Рис. 4.1. Соответствие текстов и коэффициентов тематической
близости
Смысл этого условия заключается в том, что тематически
близкие тексты T3 и T2,
будут одинаково тематически близки по отношению к T1.
Точнее сказать, чем выше тематическая близости текстов T3
и T2, тем меньше разница тематической
близости этих текстов по отношению к T1. 1 в
нашем случае соответствует максимальному значению тематической близости.
На рис. 4.2 приведен график, соответствующий условию (4.1).

Рис. 4.2. График распределения величин тематической близости
Вычисляя w1, w2, w3 для
некоторой комбинации из трех документов, будем формировать распределение
полученных величин в соответствии с осями графика (рис. 4.2). Результат
сходимости идеального графика с графиком, полученным в результате
экспериментальных исследований, будет характеризовать корректность
предложенного в данной работе алгоритма вычисления степени тематической
принадлежности текста к образцу, а вместе с ним и метода частотно-контекстной
классификации тематики текста.
Вместе с тем, говорить о полной корректности и адекватности указанного
выше метода и алгоритма по сходимости условия (4.1), безусловно, не правомерно,
это всего лишь один из критериев. Критерий весьма показательный и наглядный, но,
тем не менее, недостаточный. Дальнейшую проверку необходимо выполнять на основе
конкретных величин, сравнивая вычисленные оценки тематической близости с
экспертными оценками по некоторой заданной коллекции текстов. Такая проверка
уместна и адекватна только в контексте проверки алгоритма поиска значений
информационных признаков тематики текста, т.е. алгоритм вычисления степени
тематической принадлежности текста к образцу и алгоритм поиска значений
информационных признаков тематики текста необходимо оценивать вместе,
одновременно. Сами по себе вычисленные значения тематической близости ни о чем
не говорят, их необходимо сравнивать с экспертными оценками и на основе
сравнения делать выводы о корректности представленного метода и алгоритмов.
3) Алгоритм поиска значений информационных признаков
тематики текста.
Проверку данного алгоритма осуществим путем проведения
нескольких серий экспериментов. Для каждой серии будут заданы экспертные оценки
тематической близости некоторых текстов, по этим оценкам будет осуществлен
подбор оптимальных параметров и последующее вычисление тематической близости текстов.
После этого проанализируем полученные результаты.
4) Сравнение точности вычисления тематической близости.
Помимо проверки корректности и адекватности указанного выше
метода и алгоритмов необходимо оценить их эффективность в сравнении с уже
существующими подходами. Однако здесь существует ряд сложностей.
Сравнение алгоритма поиска значений информационных признаков
тематики текста с аналогичным ему стандартным алгоритмом не представляется
возможным в ввиду отсутствия последнего.
Сравнение эффективности выделения тематики также
представляется затруднительным по уже перечисленным выше соображениям
относительно исключительной субъективности самого понятия тематики.
Единственно приемлемым вариантом какой-то сравнительной
оценки эффективности предложенного в данной работе метода и алгоритмов
тематического анализа является сравнение точности вычислений тематической
близости предложенным в работе алгоритмом с точностью вычислений, полученных
стандартным способом.
Экспериментальные исследования будем проводить на заданной
коллекции текстов, содержание текстов приводится в приложении.
Тексты именуются следующим образом:
n_m
n – номер тематической группы
m – номер в подгруппе
В тестовой коллекции выделены следующие тематические группы:
| 1) Пушкин - Любовь |
1_1, 1_2, 1_3 |
| 2) Пушкин - Свобода |
2_1, 2_2, 2_3 |
| 3) Пушкин - Природа |
3_1, 3_2, 3_3 |
| 4) Генетические алгоритмы |
4_1, 4_2, 4_3 |
Первые три группы тематически близки, объединяет их анализ
творчества Александра Сергеевича Пушкина. Каждая отдельная группа имеет свою
характерную тематическую направленность. Это необходимо, чтобы точнее оценить
корректность вычисления тематической близости текстов.
Тексты 1,2,3-й группы сформированы на основе школьных
сочинений по анализу творчества поэта. Тексты 4-й группы сформированы на основе
обзорных статей по генетическим алгоритмам.
Характеристики текстов
Таблица 4.1
| |
1_1 |
1_2 |
1_3 |
2_1 |
2_2 |
2_3 |
3_1 |
3_2 |
3_3 |
4_1 |
4_2 |
4_3 |
| n(I) |
246 |
203 |
146 |
275 |
250 |
195 |
327 |
315 |
361 |
192 |
363 |
206 |
| n(F) |
385 |
299 |
175 |
327 |
329 |
248 |
459 |
482 |
456 |
352 |
707 |
361 |
| n(I)/n(F) |
0.64 |
0.68 |
0.83 |
0.84 |
0.76 |
0.79 |
0.71 |
0.65 |
0.79 |
0.55 |
0.51 |
0.57 |
n(I) – количество уникальных слов текста;
n(F) – количество слов в тексте;
n(I) / n(F) – соотношение характеризующее адекватность
тематической классификации;
n(I) и
n(F) приводятся с учетом
предварительной подготовки текстов (с учетом исключения “стоп-слов” – союзов,
местоимений и т.д.).
4.2.1. Автоматизированное выделение тематики
Проведем серию экспериментальных исследований программной
реализации представленного ранее метода частотно-контекстной классификации для случая,
когда выделение тематики осуществляется системой самостоятельно (в отличие от
режима дополнения множества ключевых слов заданных пользователем).
Далее в таблице приводятся списки слов и их веса
(определяющие значимость данных слов в тематике), полученных в результате
выделения тематики. Каждая таблица разделена на четыре столбца, в заголовке
каждого из них параметры, использованные при выделении тематики.
Первый параметр соответствует порогу, используемому для
выделения первичного набора ключевых элементов. Порог задается в процентах от
максимально возможной частоты некоторого слова данного текста. Все
информационные элементы, частота которых равна или превышает порог, входят в
результирующую выборку.
Второй параметр – это окрестность, в которой происходит анализ
контекста. На основе этой величины формируется набор уточняющих информационных
элементов. В таблице приводится общее множество ключевых элементов,
сформированное из первичного множества и уточняющего множества.
Пример задания параметров:
80, 0.
80 – процент от максимальной частоты, определяющий порог.
0 – окрестность.
Данный пример – это вариант стандартного выделения тематики,
без учета уточняющего множества (т.к. окрестность равна 0).
Примечания:
- первое слово в списке соответствует наиболее часто
встречающемуся слову в тексте, и его частота – соответствует максимальной
частоте (относительно которой задается порог);
- особенность данной алгоритмической реализации предполагает
исключение слов из результирующей выборки, если количество их повторений не
превышало единицу.
Результат анализа текста 4_1.
Таблица 4.2
| 80, 0 |
80, 1 |
80, 5 |
80, 10 |
| популяция |
11 |
популяция |
11 |
популяция |
11 |
популяция |
11 |
| особь |
11 |
особь |
11 |
особь |
11 |
особь |
11 |
| га |
10 |
га |
10 |
га |
10 |
га |
10 |
| оператор |
9 |
оператор |
9 |
оператор |
9 |
оператор |
9 |
| |
|
скрещивание |
5 |
приспособленность |
7 |
приспособленность |
7 |
| |
|
селекция |
4 |
скрещивание |
6 |
мутация |
7 |
| |
|
приспособленный |
3 |
алгоритм |
6 |
хромосома |
6 |
| |
|
алгоритм |
3 |
хромосома |
5 |
скрещивание |
6 |
| |
|
хромосома |
2 |
селекция |
5 |
отбор |
6 |
| |
|
приводить |
2 |
рулетка |
5 |
алгоритм |
6 |
| |
|
приспособленность |
2 |
мутация |
5 |
селекция |
5 |
| |
|
одноточечный |
2 |
решение |
4 |
рулетка |
5 |
| |
|
|
|
поколение |
4 |
ген |
5 |
| |
|
|
|
отбор |
4 |
решение |
4 |
| |
|
|
|
генетический |
4 |
поколение |
4 |
| |
|
|
|
турнир |
3 |
генетический |
4 |
| |
|
|
|
приспособленный |
3 |
точка |
3 |
| |
|
|
|
одноточечный |
3 |
турнир |
3 |
| |
|
|
|
метод |
3 |
сектор |
3 |
| |
|
|
|
задача |
3 |
соответствующий |
3 |
| |
|
|
|
ген |
3 |
приспособленный |
3 |
| |
|
|
|
вероятность |
3 |
одноточечный |
3 |
| |
|
|
|
selection |
3 |
метод |
3 |
| |
|
|
|
характеристика |
2 |
изменение |
3 |
| |
|
|
|
следующий |
2 |
задача |
3 |
| |
|
|
|
сектор |
2 |
вероятность |
3 |
| |
|
|
|
соответствующий |
2 |
выбираться |
3 |
| |
|
|
|
потомок |
2 |
selection |
3 |
| |
|
|
|
пропорциональный |
2 |
эволюция |
2 |
| |
|
|
|
приводить |
2 |
характеристика |
2 |
| |
|
|
|
осуществлять |
2 |
турнирный |
2 |
| |
|
|
|
оптимальный |
2 |
сегмент |
2 |
| |
|
|
|
кроссовер |
2 |
стохастический |
2 |
| |
|
|
|
колесо |
2 |
следующий |
2 |
| |
|
|
|
выбираться |
2 |
разрыв |
2 |
| |
|
|
|
|
|
приводить |
2 |
| |
|
|
|
|
|
потомок |
2 |
| |
|
|
|
|
|
пропорциональный |
2 |
| |
|
|
|
|
|
оценка |
2 |
| |
|
|
|
|
|
осуществлять |
2 |
| |
|
|
|
|
|
оптимальный |
2 |
| |
|
|
|
|
|
кроссовер |
2 |
| |
|
|
|
|
|
комбинация |
2 |
| |
|
|
|
|
|
колесо |
2 |
Результат анализа текста 4_1.
Таблица 4.3
| 60, 0 |
60, 1 |
60, 5 |
60, 10 |
| популяция |
11 |
популяция |
11 |
популяция |
11 |
популяция |
11 |
| особь |
11 |
особь |
11 |
особь |
11 |
особь |
11 |
| га |
10 |
га |
10 |
га |
10 |
га |
10 |
| оператор |
9 |
оператор |
9 |
оператор |
9 |
оператор |
9 |
| хромосома |
7 |
хромосома |
7 |
хромосома |
7 |
хромосома |
7 |
| приспособленность |
7 |
приспособленность |
7 |
приспособленность |
7 |
приспособленность |
7 |
| мутация |
7 |
мутация |
7 |
мутация |
7 |
мутация |
7 |
| скрещивание |
6 |
скрещивание |
6 |
скрещивание |
6 |
скрещивание |
6 |
| отбор |
6 |
отбор |
6 |
отбор |
6 |
отбор |
6 |
| алгоритм |
6 |
алгоритм |
6 |
алгоритм |
6 |
алгоритм |
6 |
| |
|
селекция |
5 |
селекция |
5 |
селекция |
5 |
| |
|
генетический |
4 |
рулетка |
5 |
рулетка |
5 |
| |
|
приспособленный |
3 |
ген |
5 |
ген |
5 |
| |
|
турнирный |
2 |
решение |
4 |
решение |
4 |
| |
|
приводить |
2 |
поколение |
4 |
поколение |
4 |
| |
|
одноточечный |
2 |
генетический |
4 |
генетический |
4 |
| |
|
ген |
2 |
турнир |
3 |
турнир |
3 |
| |
|
вероятность |
2 |
сектор |
3 |
точка |
3 |
| |
|
|
|
приспособленный |
3 |
соответствовать |
3 |
| |
|
|
|
одноточечный |
3 |
соответствующий |
3 |
| |
|
|
|
метод |
3 |
сектор |
3 |
| |
|
|
|
задача |
3 |
приспособленный |
3 |
| |
|
|
|
вероятность |
3 |
одноточечный |
3 |
| |
|
|
|
selection |
3 |
метод |
3 |
| |
|
|
|
эволюция |
2 |
комбинация |
3 |
| |
|
|
|
характеристика |
2 |
изменение |
3 |
| |
|
|
|
турнирный |
2 |
задача |
3 |
| |
|
|
|
соответствовать |
2 |
гиперкуб |
3 |
| |
|
|
|
следующий |
2 |
выбираться |
3 |
| |
|
|
|
стохастический |
2 |
вероятность |
3 |
| |
|
|
|
соответствующий |
2 |
selection |
3 |
| |
|
|
|
приводить |
2 |
эволюция |
2 |
| |
|
|
|
пропорциональный |
2 |
характеристика |
2 |
| |
|
|
|
потомок |
2 |
турнирный |
2 |
| |
|
|
|
оптимальный |
2 |
строка |
2 |
| |
|
|
|
оценка |
2 |
сегмент |
2 |
| |
|
|
|
осуществлять |
2 |
следующий |
2 |
| |
|
|
|
кроссовер |
2 |
стохастический |
2 |
| |
|
|
|
комбинация |
2 |
разбиение |
2 |
| |
|
|
|
колесо |
2 |
разрыв |
2 |
| |
|
|
|
изменение |
2 |
приводить |
2 |
| |
|
|
|
выбираться |
2 |
потомок |
2 |
| |
|
|
|
|
|
пропорциональный |
2 |
| |
|
|
|
|
|
оценка |
2 |
| |
|
|
|
|
|
оптимальный |
2 |
| |
|
|
|
|
|
осуществлять |
2 |
| |
|
|
|
|
|
колесо |
2 |
| |
|
|
|
|
|
кроссовер |
2 |
| |
|
|
|
|
|
двоичный |
2 |
| |
|
|
|
|
|
бинарный |
2 |
Результат анализа текста 4_1.
Таблица 4.4
| 40, 0 |
40, 1 |
40, 5 |
40, 10 |
| популяция |
11 |
популяция |
11 |
популяция |
11 |
популяция |
11 |
| особь |
11 |
особь |
11 |
особь |
11 |
особь |
11 |
| га |
10 |
га |
10 |
га |
10 |
га |
10 |
| оператор |
9 |
оператор |
9 |
оператор |
9 |
оператор |
9 |
| хромосома |
7 |
хромосома |
7 |
хромосома |
7 |
хромосома |
7 |
| приспособленность |
7 |
приспособленность |
7 |
приспособленность |
7 |
приспособленность |
7 |
| мутация |
7 |
мутация |
7 |
мутация |
7 |
мутация |
7 |
| скрещивание |
6 |
скрещивание |
6 |
скрещивание |
6 |
скрещивание |
6 |
| отбор |
6 |
отбор |
6 |
отбор |
6 |
отбор |
6 |
| алгоритм |
6 |
алгоритм |
6 |
алгоритм |
6 |
алгоритм |
6 |
| селекция |
5 |
селекция |
5 |
селекция |
5 |
селекция |
5 |
| рулетка |
5 |
рулетка |
5 |
рулетка |
5 |
рулетка |
5 |
| ген |
5 |
ген |
5 |
ген |
5 |
ген |
5 |
| точка |
4 |
точка |
4 |
точка |
4 |
точка |
4 |
| строка |
4 |
строка |
4 |
строка |
4 |
строка |
4 |
| решение |
4 |
решение |
4 |
решение |
4 |
решение |
4 |
| поколение |
4 |
поколение |
4 |
поколение |
4 |
поколение |
4 |
| задача |
4 |
задача |
4 |
задача |
4 |
задача |
4 |
| генетический |
4 |
генетический |
4 |
генетический |
4 |
генетический |
4 |
| |
|
разрыв |
3 |
турнир |
3 |
турнир |
3 |
| |
|
приспособленный |
3 |
соответствующий |
3 |
соответствующий |
3 |
| |
|
турнирный |
2 |
сектор |
3 |
сектор |
3 |
| |
|
турнир |
2 |
соответствовать |
3 |
соответствовать |
3 |
| |
|
сектор |
2 |
разрыв |
3 |
разрыв |
3 |
| |
|
соответствующий |
2 |
приспособленный |
3 |
приспособленный |
3 |
| |
|
приводить |
2 |
одноточечный |
3 |
одноточечный |
3 |
| |
|
одноточечный |
2 |
метод |
3 |
метод |
3 |
| |
|
колесо |
2 |
кодировка |
3 |
кодировка |
3 |
| |
|
возможный |
2 |
гиперкуб |
3 |
комбинация |
3 |
| |
|
выбираться |
2 |
вероятность |
3 |
изменение |
3 |
| |
|
вероятность |
2 |
возможный |
3 |
гиперкуб |
3 |
| |
|
бинарный |
2 |
выбираться |
3 |
вероятность |
3 |
| |
|
|
|
selection |
3 |
выбираться |
3 |
| |
|
|
|
эволюция |
2 |
возможный |
3 |
| |
|
|
|
характеристика |
2 |
бинарный |
3 |
| |
|
|
|
турнирный |
2 |
selection |
3 |
| |
|
|
|
стохастический |
2 |
эволюция |
2 |
| |
|
|
|
сегмент |
2 |
характеристика |
2 |
| |
|
|
|
следующий |
2 |
турнирный |
2 |
| |
|
|
|
разбиение |
2 |
стохастический |
2 |
| |
|
|
|
пропорциональный |
2 |
следующий |
2 |
| |
|
|
|
потомок |
2 |
сегмент |
2 |
| |
|
|
|
приводить |
2 |
разбиение |
2 |
| |
|
|
|
оценка |
2 |
приводить |
2 |
| |
|
|
|
осуществлять |
2 |
потомок |
2 |
| |
|
|
|
оптимальный |
2 |
пропорциональный |
2 |
| |
|
|
|
комбинация |
2 |
оценка |
2 |
| |
|
|
|
колесо |
2 |
осуществлять |
2 |
| |
|
|
|
кроссовер |
2 |
оптимальный |
2 |
| |
|
|
|
изменение |
2 |
колесо |
2 |
| |
|
|
|
двоичный |
2 |
кроссовер |
2 |
| |
|
|
|
бит |
2 |
код |
2 |
| |
|
|
|
бинарный |
2 |
двоичный |
2 |
| |
|
|
|
|
|
бит |
2 |
Результат анализа текста 1_1.
Таблица 4.5
| 80, 0 |
80, 1 |
80, 5 |
80, 10 |
| пушкин |
20 |
пушкин |
20 |
пушкин |
20 |
Пушкин |
20 |
| поэт |
17 |
поэт |
17 |
поэт |
17 |
поэт |
17 |
| стихотворение |
16 |
стихотворение |
16 |
стихотворение |
16 |
стихотворение |
16 |
| |
|
лирик |
6 |
лирик |
10 |
лирик |
12 |
| |
|
творчество |
5 |
любовный |
9 |
любовный |
10 |
| |
|
холм |
2 |
творчество |
6 |
творчество |
6 |
| |
|
период |
2 |
переживание |
4 |
поэзия |
4 |
| |
|
оживать |
2 |
тема |
3 |
переживание |
4 |
| |
|
любовный |
2 |
романтический |
3 |
южный |
3 |
| |
|
возвышенный |
2 |
поэзия |
3 |
тема |
3 |
| |
|
|
|
оживать |
3 |
романтический |
3 |
| |
|
|
|
любимая |
3 |
период |
3 |
| |
|
|
|
говориться |
3 |
оживать |
3 |
| |
|
|
|
возлюбленный |
3 |
обращаться |
3 |
| |
|
|
|
возвышенный |
3 |
нежный |
3 |
| |
|
|
|
альбом |
3 |
любимая |
3 |
| |
|
|
|
яркий |
2 |
герой |
3 |
| |
|
|
|
южный |
2 |
говориться |
3 |
| |
|
|
|
чудной |
2 |
возвышенный |
3 |
| |
|
|
|
холм |
2 |
возлюбленный |
3 |
| |
|
|
|
утаить |
2 |
альбом |
3 |
| |
|
|
|
табак |
2 |
яркий |
2 |
| |
|
|
|
трагичный |
2 |
шутка |
2 |
| |
|
|
|
ссылка |
2 |
чудной |
2 |
| |
|
|
|
стих |
2 |
холм |
2 |
| |
|
|
|
связать |
2 |
утаить |
2 |
| |
|
|
|
ранний |
2 |
табак |
2 |
| |
|
|
|
предмет |
2 |
трагичный |
2 |
| |
|
|
|
период |
2 |
ссылка |
2 |
| |
|
|
|
образ |
2 |
сердечный |
2 |
| |
|
|
|
обращаться |
2 |
стих |
2 |
| |
|
|
|
отечество |
2 |
связать |
2 |
| |
|
|
|
нюхать |
2 |
ранний |
2 |
| |
|
|
|
нежный |
2 |
предмет |
2 |
| |
|
|
|
мгновение |
2 |
отечество |
2 |
| |
|
|
|
легкий |
2 |
образ |
2 |
| |
|
|
|
красавица |
2 |
нюхать |
2 |
| |
|
|
|
красота |
2 |
мечта |
2 |
| |
|
|
|
идеал |
2 |
мгновение |
2 |
| |
|
|
|
источник |
2 |
легкий |
2 |
| |
|
|
|
жанр |
2 |
красавица |
2 |
| |
|
|
|
глубокий |
2 |
красота |
2 |
| |
|
|
|
грузия |
2 |
источник |
2 |
| |
|
|
|
герой |
2 |
идеал |
2 |
| |
|
|
|
грустный |
2 |
жанр |
2 |
| |
|
|
|
вечный |
2 |
грузия |
2 |
| |
|
|
|
воспоминание |
2 |
грустный |
2 |
| |
|
|
|
|
|
глубокий |
2 |
| |
|
|
|
|
|
вечный |
2 |
| |
|
|
|
|
|
весна |
2 |
| |
|
|
|
|
|
воспоминание |
2 |
Результат анализа текста 1_1.
Таблица 4.6
| 60, 0 |
60, 1 |
60, 5 |
60, 10 |
| пушкин |
20 |
пушкин |
20 |
пушкин |
20 |
пушкин |
20 |
| поэт |
17 |
поэт |
17 |
поэт |
17 |
поэт |
17 |
| стихотворение |
16 |
стихотворение |
16 |
стихотворение |
16 |
стихотворение |
16 |
| лирик |
12 |
лирик |
12 |
лирик |
12 |
лирик |
12 |
| |
|
любовный |
8 |
любовный |
10 |
любовный |
10 |
| |
|
творчество |
6 |
творчество |
6 |
творчество |
6 |
| |
|
холм |
2 |
переживание |
4 |
поэзия |
4 |
| |
|
стих |
2 |
южный |
3 |
переживание |
4 |
| |
|
период |
2 |
тема |
3 |
южный |
3 |
| |
|
переживание |
2 |
романтический |
3 |
тема |
3 |
| |
|
оживать |
2 |
период |
3 |
романтический |
3 |
| |
|
возвышенный |
2 |
поэзия |
3 |
период |
3 |
| |
|
|
|
оживать |
3 |
оживать |
3 |
| |
|
|
|
любимая |
3 |
обращаться |
3 |
| |
|
|
|
говориться |
3 |
нежный |
3 |
| |
|
|
|
возлюбленный |
3 |
любимая |
3 |
| |
|
|
|
возвышенный |
3 |
герой |
3 |
| |
|
|
|
альбом |
3 |
говориться |
3 |
| |
|
|
|
яркий |
2 |
возвышенный |
3 |
| |
|
|
|
чудной |
2 |
возлюбленный |
3 |
| |
|
|
|
холм |
2 |
альбом |
3 |
| |
|
|
|
утаить |
2 |
яркий |
2 |
| |
|
|
|
трагичный |
2 |
шутка |
2 |
| |
|
|
|
табак |
2 |
чудной |
2 |
| |
|
|
|
ссылка |
2 |
холм |
2 |
| |
|
|
|
стих |
2 |
утаить |
2 |
| |
|
|
|
связать |
2 |
табак |
2 |
| |
|
|
|
ранний |
2 |
трагичный |
2 |
| |
|
|
|
петербургский |
2 |
ссылка |
2 |
| |
|
|
|
предмет |
2 |
сердечный |
2 |
| |
|
|
|
обращаться |
2 |
стих |
2 |
| |
|
|
|
образ |
2 |
связать |
2 |
| |
|
|
|
отечество |
2 |
ранний |
2 |
| |
|
|
|
нюхать |
2 |
предмет |
2 |
| |
|
|
|
нежный |
2 |
петербургский |
2 |
| |
|
|
|
мгновение |
2 |
отечество |
2 |
| |
|
|
|
легкий |
2 |
образ |
2 |
| |
|
|
|
красавица |
2 |
нюхать |
2 |
| |
|
|
|
красота |
2 |
мечта |
2 |
| |
|
|
|
идеал |
2 |
мгновение |
2 |
| |
|
|
|
источник |
2 |
легкий |
2 |
| |
|
|
|
жанр |
2 |
красавица |
2 |
| |
|
|
|
грустный |
2 |
красота |
2 |
| |
|
|
|
грузия |
2 |
источник |
2 |
| |
|
|
|
герой |
2 |
идеал |
2 |
| |
|
|
|
глубокий |
2 |
жанр |
2 |
| |
|
|
|
вечный |
2 |
грузия |
2 |
| |
|
|
|
весна |
2 |
грустный |
2 |
| |
|
|
|
воспоминание |
2 |
глубокий |
2 |
| |
|
|
|
|
|
вечный |
2 |
| |
|
|
|
|
|
весна |
2 |
| |
|
|
|
|
|
воспоминание |
2 |
Результат анализа текста 1_1.
Таблица 4.7
| 40, 0 |
40, 1 |
40, 5 |
40, 10 |
| пушкин |
20 |
пушкин |
20 |
пушкин |
20 |
пушкин |
20 |
| поэт |
17 |
поэт |
17 |
поэт |
17 |
поэт |
17 |
| стихотворение |
16 |
стихотворение |
16 |
стихотворение |
16 |
стихотворение |
16 |
| лирик |
12 |
лирик |
12 |
лирик |
12 |
лирик |
12 |
| любовный |
10 |
любовный |
10 |
любовный |
10 |
любовный |
10 |
| |
|
творчество |
6 |
творчество |
6 |
творчество |
6 |
| |
|
переживание |
3 |
переживание |
4 |
поэзия |
4 |
| |
|
холм |
2 |
южный |
3 |
переживание |
4 |
| |
|
стих |
2 |
тема |
3 |
южный |
3 |
| |
|
предмет |
2 |
романтический |
3 |
тема |
3 |
| |
|
период |
2 |
период |
3 |
романтический |
3 |
| |
|
оживать |
2 |
поэзия |
3 |
период |
3 |
| |
|
говориться |
2 |
оживать |
3 |
оживать |
3 |
| |
|
весна |
2 |
любимая |
3 |
обращаться |
3 |
| |
|
возвышенный |
2 |
говориться |
3 |
нежный |
3 |
| |
|
|
|
возлюбленный |
3 |
любимая |
3 |
| |
|
|
|
возвышенный |
3 |
герой |
3 |
| |
|
|
|
альбом |
3 |
говориться |
3 |
| |
|
|
|
яркий |
2 |
возвышенный |
3 |
| |
|
|
|
чудной |
2 |
возлюбленный |
3 |
| |
|
|
|
холм |
2 |
альбом |
3 |
| |
|
|
|
утаить |
2 |
яркий |
2 |
| |
|
|
|
трагичный |
2 |
шутка |
2 |
| |
|
|
|
табак |
2 |
чудной |
2 |
| |
|
|
|
ссылка |
2 |
холм |
2 |
| |
|
|
|
стих |
2 |
утаить |
2 |
| |
|
|
|
связать |
2 |
табак |
2 |
| |
|
|
|
ранний |
2 |
трагичный |
2 |
| |
|
|
|
петербургский |
2 |
ссылка |
2 |
| |
|
|
|
предмет |
2 |
сердечный |
2 |
| |
|
|
|
обращаться |
2 |
стих |
2 |
| |
|
|
|
образ |
2 |
связать |
2 |
| |
|
|
|
отечество |
2 |
ранний |
2 |
| |
|
|
|
нюхать |
2 |
предмет |
2 |
| |
|
|
|
нежный |
2 |
петербургский |
2 |
| |
|
|
|
мгновение |
2 |
отечество |
2 |
| |
|
|
|
легкий |
2 |
образ |
2 |
| |
|
|
|
красавица |
2 |
нюхать |
2 |
| |
|
|
|
красота |
2 |
мечта |
2 |
| |
|
|
|
идеал |
2 |
мгновение |
2 |
| |
|
|
|
источник |
2 |
легкий |
2 |
| |
|
|
|
жанр |
2 |
красавица |
2 |
| |
|
|
|
грустный |
2 |
красота |
2 |
| |
|
|
|
грузия |
2 |
источник |
2 |
| |
|
|
|
герой |
2 |
идеал |
2 |
| |
|
|
|
глубокий |
2 |
жанр |
2 |
| |
|
|
|
вечный |
2 |
грузия |
2 |
| |
|
|
|
весна |
2 |
грустный |
2 |
| |
|
|
|
воспоминание |
2 |
глубокий |
2 |
| |
|
|
|
|
|
вечный |
2 |
| |
|
|
|
|
|
весна |
2 |
| |
|
|
|
|
|
воспоминание |
2 |
4.2.2. Выделение тематики расширением первичного набора ключевых слов,
задаваемых пользователем.
Данный вариант предполагает задание пользователем некоторого
набора ключевых слов и расширение этого набора системой за счет контекстного
анализа.
Вариант предусматривает работу как с отдельным документом,
так и с обобщенным множеством тематически близких текстов. В этом случае
каждый текст дополняет общую структурную модель M(
I, R). Совокупность текстов образует
общую структуру, и контекстный анализ осуществляется уже на основе общей информационной
структуры.
В таблице приводятся списки ключевых слов, заданных
пользователем, и списки, полученные в результате контекстного анализа
обобщенного множества текстов.
Список ключевых слов, полученных в результате работы
программы, вместе с их весами приводится справа от списка, заданного
пользователем.
Результат анализа текстов: 4_1, 4_2, 4_3.
Таблица 4.8
| популяция |
популяция |
21 |
отбор |
отбор |
17 |
| хромосома |
хромосома |
18 |
мутация |
мутация |
13 |
| |
особь |
7 |
|
скрещивание |
6 |
| |
отбор |
5 |
|
популяция |
6 |
| |
индивидуум |
5 |
|
приспособленность |
5 |
| |
скрещивание |
4 |
|
кроссовер |
5 |
| |
набор |
4 |
|
естественный |
5 |
| |
мутация |
4 |
|
алгоритм |
5 |
| |
генетический |
4 |
|
ген |
4 |
| |
следующий |
3 |
|
эволюция |
3 |
| |
случайный |
3 |
|
хромосома |
3 |
| |
поколение |
3 |
|
селекция |
3 |
| |
кроссовер |
3 |
|
поколение |
3 |
| |
ген |
3 |
|
оператор |
3 |
| |
эволюция |
2 |
|
изменение |
3 |
| |
частями |
2 |
|
генетический |
3 |
| |
свойство |
2 |
|
турнирный |
2 |
| |
сектор |
2 |
|
реализовать |
2 |
| |
решение |
2 |
|
особь |
2 |
| |
приспособленный |
2 |
|
наследование |
2 |
| |
приспособленность |
2 |
|
метод |
2 |
| |
объесть |
2 |
|
механизм |
2 |
| |
осуществлять |
2 |
|
индивидуум |
2 |
| |
одноточечный |
2 |
|
га |
2 |
| |
изменение |
2 |
|
вероятность |
2 |
| |
задача |
2 |
|
selection |
2 |
| |
генерация |
2 |
|
|
|
| |
вложение |
2 |
|
|
|
| |
вектор |
2 |
|
|
|
| |
вероятность |
2 |
|
|
|
| |
алгоритм |
2 |
|
|
|
Результат анализа текстов: 1_1, 1_2, 1_3, 2_1, 2_2, 2_3, 3_1, 3_2, 3_3.
Таблица 4.9
| осень |
осень |
17 |
свобода |
свобода |
14 |
| поэзия |
поэзия |
11 |
царь |
царь |
9 |
| |
пушкин |
10 |
|
рабство |
4 |
| |
красота |
6 |
|
пушкин |
4 |
| |
стихотворение |
4 |
|
поэт |
4 |
| |
поэт |
4 |
|
стихотворение |
3 |
| |
любимый |
4 |
|
учиться |
2 |
| |
посвященный |
3 |
|
темница |
2 |
| |
описание |
3 |
|
рухнуть |
2 |
| |
зима |
3 |
|
примета |
2 |
| |
фрагмент |
2 |
|
просвещение |
2 |
| |
творчество |
2 |
|
падший |
2 |
| |
мотив |
2 |
|
просвещенный |
2 |
| |
лирик |
2 |
|
пасть |
2 |
| |
лета |
2 |
|
отдать |
2 |
| |
легкий |
2 |
|
отечество |
2 |
| |
автор |
2 |
|
награда |
2 |
| |
|
|
|
наказание |
2 |
| |
|
|
|
мания |
2 |
| |
|
|
|
личной |
2 |
| |
|
|
|
кров |
2 |
| |
|
|
|
днесь |
2 |
| |
|
|
|
взойти |
2 |
Как было уже сказано выше, корректность вычисления
тематической близости будем оценивать по сходимости условия 4.1.
В качестве тестовых текстов возьмем тексты групп
1, 2, 3. Кроме того, сформируем дополнительное множество тематически
близких им текстов на основе конкатенации текстов из указанных групп (в
результате получится множество тематически близких текстов). Это необходимо для
получения достаточного количества комбинаций из трех текстов, позволяющих
построить распределение вычисленных значений тематической близости.
Результаты распределения вычисленных значений приводятся
ниже.
Также приводятся значения информационных признаков тематики –
параметров, использованных при выделении тематики: p
– порог (используемый при выделении ключевых слов),
r – окрестность (на основе которой
выполняется дополнение первичного множества ключевых слов).
По оси абсцисс будем откладывать  , по оси ординат , по оси ординат  . .
p = 80%, r = 5

Рис. 3.4. Распределение значений тематической близости
p = 70%, r = 10

Рис. 3.5. Распределение значений тематической близости
p = 60%, r = 5

Рис. 3.6. Распределение значений тематической близости
p = 60%, r = 0

Рис. 3.7. Распределение значений тематической близости
p = 60%, r = 20

Рис. 3.8. Распределение значений тематической близости
Как видно из полученных результатов, условие (4.1) действительно выполняется.
Проведем N серий
экспериментов программной реализации алгоритма поиска значений информационных
признаков тематики текста.
В каждой серии зададим некоторые экспертные оценки, и затем
на основе найденных значений вычислим тематическую близость документов.
В таблице 4.10 приведены экспертные оценки для каждой серии
экспериментов.
В таблице 4.11 приведены результаты вычисленных оценок тематической близости.
percent – порог;
range – окрестность;
scale – масштабирующий коэффициент;
diff – разница соотношений оценок при оптимальных параметрах (вычисленная по формуле 2.1).
Экспертные оценки.
Таблица 4.10
| N |
Документ образец |
Анализируемый документ 1 |
Экспертная оценка |
Анализируемый документ 2 |
Экспертная оценка |
| 1 |
1_2 |
1_1 |
0.6 |
1_3 |
0.6 |
| 2 |
1_2 |
2_3 |
0.2 |
3_1 |
0.46 |
| 3 |
1_1 |
1_2 |
0.6 |
2_1 |
0.2 |
| 4 |
1_1 |
2_2 |
0.42 |
3_2 |
0.3 |
| 5 |
2_1 |
2_2 |
0.6 |
2_3 |
0.6 |
| 6 |
2_1 |
1_1 |
0.43 |
3_3 |
0.15 |
| 7 |
3_1 |
3_2 |
0.6 |
2_1 |
0.2 |
| 8 |
3_1 |
1_1 |
0.64 |
1_3 |
0.22 |
Вычисленные оценки.
Таблица 4.11
| N |
percent |
range |
scale |
diff |
|
1_1 |
1_2 |
1_3 |
2_1 |
2_2 |
2_3 |
3_1 |
3_2 |
3_3 |
| 1 |
90 |
1 |
8.69 |
0.01 |
1_2 |
0.6 |
1 |
0.6 |
0.12 |
0.06 |
0.2 |
0.46 |
0.53 |
0.21 |
| 2 |
90 |
1 |
8.76 |
0.00 |
1_2 |
0.61 |
1 |
0.6 |
0.12 |
0.06 |
0.2 |
0.46 |
0.53 |
0.21 |
| 3 |
80 |
9 |
16.59 |
0.02 |
1_1 |
1 |
0.6 |
0.21 |
0.2 |
0.42 |
0.14 |
0.56 |
0.3 |
0.25 |
| 4 |
80 |
9 |
16.54 |
0.00 |
1_1 |
1 |
0.6 |
0.21 |
0.2 |
0.42 |
0.14 |
0.56 |
0.3 |
0.25 |
| 5 |
80 |
2 |
18.03 |
0.01 |
2_1 |
0.43 |
0.13 |
0.24 |
1 |
0.6 |
0.6 |
0.45 |
0.08 |
0.15 |
| 6 |
80 |
2 |
18.03 |
0.07 |
2_1 |
0.43 |
0.13 |
0.24 |
1 |
0.6 |
0.6 |
0.45 |
0.08 |
0.15 |
| 7 |
90 |
12 |
17.57 |
0.04 |
3_1 |
0.64 |
0.38 |
0.22 |
0.2 |
0.21 |
0.24 |
1 |
0.6 |
0.35 |
| 8 |
90 |
12 |
17.69 |
0.00 |
3_1 |
0.64 |
0.38 |
0.22 |
0.2 |
0.21 |
0.24 |
1 |
0.61 |
0.35 |
В таблице 4.11 приведены результаты экспериментальных исследований.
Для каждой серии определены оптимальные параметры (значения
информационных признаков тематики текста) и на основе этих параметров, выполнено
выделение тематики и расчет тематической близости (с учетом масштабирующего
коэффициента).
Для каждой серии определен текст-образец, относительно
которого выполняется вычисление тематической близости. Для серии 1, 2 – это
1_2, для серии 3,4 – это 1_1, для серии 5,6 – это 2_1, для серии 7,8 – это 3_1.
Таблицы 4.10 и 4.11 соотносятся между собой.
В заголовке таблице 4.11 по горизонтали перечислены тексты,
анализируемые на тематическую близость с текстом образцом. На пересечении ячеек
текста образца и текста, анализируемого на тематическую близость, – вычисленная
оценка тематической близости.
Можно обратить внимание, что вычисленная оценка практически
идентична оценке, заданной экспертом, diff
определяет ошибку, чем меньше diff,
тем меньше разница между вычисленными оценками и оценками, заданными экспертом.
Величина diff характеризует
точность подбора параметров, и, соответственно, характеризует все последующие
вычисления по заданным параметрам.
Качество и корректность тематического анализа, можно
определить на основе анализа таблицы 4.11.
Рассмотрим следующие характерные закономерности,
присутствующие в приведенных результатах:
1) Сходимость оценок на произвольных текстах.
Оценки тематической близости сходятся не только для тех текстов,
которые предварительно использовались для задания экспертной оценки, но и на
произвольных текстах, которые впоследствии анализировались на тематическую
близость с текстом образцом.
Рассмотрим подробнее серию 1 и 2.
Для серии 1 первоначально были заданы экспертные оценки
между текстами 1_2, 1_1, 1_3.
Соответственно экспертная оценка близости для 1_2 - 1_1
равнялась 0.6 и 1_2 - 1_3 равнялась 0.6.
Вычисленная оценка для тех же самых документов идентична
экспертной оценке, но данный критерий еще не является показателем качества и
корректности, интересно проследить, как будут себя вести вычисленные оценки для
других документов. Рассмотрим внимательно остальные оценки данной серии.
Сказать что-то относительно правильности их значений затруднительно, так как
сложно оценить с такой точностью представленные тексты и сказать, насколько
корректны вычисленные результаты. Можно лишь с некоторой степенью достоверности
предположить, что оценки близки к ожидаемым. Существует другой способ оценки
корректности.
В приведенной серии экспертные оценки выполнены для текстов
из одной тематической подгруппы. Эксперт, по сути, задает меру тематической
близости, и остальные оценки из других тематических подгрупп, по отношению к
1_2 отражают мнение эксперта. Проведем обратный эксперимент. Выберем в качестве
экспертных оценок вычисленные значения, определим оптимальные параметры и
получим уже вычисленные оценки для текстов ранее оцениваемых экспертом. По их
разнице можно определить корректность алгоритма. Серия 2, по сути, отражает
такой эксперимент.
В качестве экспертных оценок данной серии выбраны ранее
вычисленные значения, затем определены оптимальные параметры и вычислены оценки
для всей серии.
Также организованны и другие серии.
Можно видеть, что оценки практически идентичны. Это является
одним из косвенных свидетельств корректности разработанного в работе метода и
алгоритмов тематического анализа.
2) Сходимость оценок в различных сериях.
Из таблицы 4.11 выделен фрагмент, рассмотрим его подробнее:
| N |
|
1_1 |
1_2 |
2_1 |
3_1 |
| 1 |
1_2 |
0.6 |
1 |
0.12 |
0.46 |
| 3 |
1_1 |
1 |
0.6 |
0.2 |
0.56 |
| 5 |
2_1 |
0.43 |
0.13 |
1 |
0.45 |
| 7 |
3_1 |
0.64 |
0.38 |
0.2 |
1 |
В серии 1 существует вычисленная оценка для 1_2 – 2_1, она равна 0.12
В серии 5 существует вычисленная оценка 2_1 – 1_2, она равна 0.13
Для этих двух серий существует совершенно независимые оценки
тематической близости этих текстов, как видно, они практически совпадают.
Вычислим ошибку:
m = | 0.12 – 0.13 | = 0.01
Рассмотрим другие независимые оценки:
1_2 – 1_3 и 3_1 – 1_2
m = | 0.46 – 0.38 | = 0.08
1_1 – 3_1 и 3_1 – 1_1
m = | 0.56 – 0.64 | = 0.08
Полученная ошибка не превышает 0.08, если принять за 1
максимально возможную погрешность, то ошибка составляет 8% - это очень точный и
качественный результат для подобного рода вычислений.
В совокупности по рассмотренным выше закономерностям можно
сделать вывод о корректности и высокой точности, разработанного в работе метода
и алгоритмов тематического анализа.
Проведем серию вычислений тематической близости предложенным
в данной работе алгоритмом вычисления тематической близости и сравним полученную
точность с точностью вычислений, полученных одним из традиционных способов.
В большинстве информационно-поисковых систем традиционным способом
вычисления меры близости векторов является использование косинуса угла,
определяемого через скалярное произведение векторов [8]:
 , ,
где  и и  - сравниваемые вектора. - сравниваемые вектора.
После нормировки и 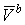 по единице выражение можно
переписать в виде по единице выражение можно
переписать в виде  . .
При сравнении точности будем руководствоваться следующими
соображениями.
Существует объективная сложность оценки точности вычислений
тематической близости, т.к. отсутствуют эталонная мера тематической близости, с
которой можно было бы сравнить вычисленные значения. Тем не менее, существует
задача оценки точности вычислений, полученных одним способом вычислений в сравнении
с другим. Было принято решение использовать косвенную оценку точности
вычислений по чувствительности алгоритма расчета тематической близости. В
данном контексте чувствительность – мера изменения тематической близости
произвольного текста по отношению к тексту-образцу, при внесении в произвольный
текст некоторого изменения.
Допустим, у нас есть оценка тематической близости
произвольного текста к тексту-образцу, пусть сравниваемые тексты одинаковы,
тогда оценка тематической близости текста по отношению к самому себе равна 1. Теперь
внесем изменение в текст, сохранив предварительно его оригинал, например, исключим
из текста каждое n-е слово. После такого изменения
снова вычислим тематическую близость полученного в результате изменения текста
по отношению к тексту-оригиналу, выступающему в качестве образца. В результате
вычисления мы получим некоторое новое значение тематической близости
w, очевидно, что это новое значение будет меньше 1, т.к.
тематика изменилась (или равно 1, если данный способ вычисления не чувствителен
к данному изменению). Отношение w / 1 или
просто w, определяет величину чувствительности. Обозначим
ее S, и запишем как:
 , ,
 , ,
|
(4.2) |
Чувствительность тем больше, чем меньше величина тематической
близости после некоторого изменения текста. Очевидна, в этом случае зависимость
чувствительности от изменения, вносимого в текст. Сама по себе эта величина не
представляет интереса, т.к. она зависит от текста и от изменений вносимых в
него. Однако ее можно сравнивать с чувствительностью, полученной для другого способа
вычисления тематической близости при тех же условиях – на том же тексте, с тем
же изменением.
Величину сравниваемой чувствительности можно записать как:
 , ,
|
(4.3) |
где: S и S’ – чувствительности, полученные разными способами
вычисления тематической близости. Величина  показывает, на сколько
чувствительность способа используемого при вычислении S
больше чувствительности способа используемого при вычислении
S’. Подставляя в формулу (4.3), формулу (4.2), запишем: показывает, на сколько
чувствительность способа используемого при вычислении S
больше чувствительности способа используемого при вычислении
S’. Подставляя в формулу (4.3), формулу (4.2), запишем:
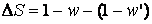 , ,
 . .
Проведем серию вычислений при различных изменениях вносимых в текст,
среднее будет
характеризовать точность одного способа в сравнении с другим.
Далее приводятся результаты вычислений для нескольких
текстов. Обозначения:
w – величина тематической близости
полученная предложенным в данной работе алгоритмом вычисления тематической
близости;
w’ – величина тематической близости
полученная в результате вычисления скалярного произведения векторов,
.
Текст 1_1.
Параметры, использованные при выделении тематики:
p = 50%, r = 0.
Численные значения 2, 3, ..., 10 характеризуют изменения,
вносимые в текст. Число соответствует исключению из текста каждого
n – го слова.
Таблица 4.12
| |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
| w |
0.36 |
0.6 |
0.57 |
0.7 |
0.62 |
0.76 |
0.65 |
0.86 |
0.84 |
| w’ |
0.95 |
1 |
0.91 |
1 |
0.91 |
1 |
0.91 |
1 |
1 |
|
0.59 |
0.4 |
0.34 |
0.3 |
0.29 |
0.24 |
0.26 |
0.14 |
0.16 |
Текст 3_2.
p = 30%, r = 0.
Таблица 4.13
| |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
| w |
0.45 |
0.33 |
0.73 |
0.69 |
0.72 |
0.68 |
0.82 |
0.76 |
0.78 |
| w’ |
0.91 |
0.51 |
0.96 |
0.9 |
0.97 |
1 |
0.92 |
0.88 |
1 |
|
0.46 |
0.18 |
0.23 |
0.21 |
0.25 |
0.32 |
0.1 |
0.12 |
0.22 |
Текст 3_1.
p = 30%, r = 0.
Таблица 4.14
| |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
| w |
0.35 |
0.42 |
0.57 |
0.7 |
0.75 |
0.8 |
0.77 |
0.86 |
0.82 |
| w’ |
0.86 |
0.65 |
0.84 |
0.92 |
0.94 |
1 |
0.93 |
1 |
1 |
|
0.51 |
0.23 |
0.27 |
0.22 |
0.19 |
0.2 |
0.16 |
0.14 |
0.18 |
Теперь можно подсчитать среднее по всем текстам. При этом стоит
учитывать один момент. Все , рассчитанные при w’
= 1, не достаточно корректно отражают измерение чувствительности, т.к. 1
означает, что данный способ не смог зафиксировать изменение тематики (при
данной модификации текста). Сравнение с ним чувствительности другого способа, в
этом случае, не корректно. При вычислении среднего будем учитывать только те
измерения, когда w’ < 1.
Полученное среднее значение = 0.28, если принять за 1 максимально
возможное ,
то % = 28%.
Таким образом, косвенная оценка представленного в данной
работе алгоритма вычисления тематической близости по сравнению со стандартным
способом расчета, характеризует повышение точности приблизительно на 28%.
Результаты экспериментальных исследований успешно подтвердили
выдвинутые ранее теоретические положения. Тестирование программной реализации разработанного
метода и алгоритмов показало высокую точность и корректность полученных
значений.
Вместе с тем, стоит отметить сложность оценки полученных
результатов, и значительное влияние субъективной составляющей, присутствующей
при оценке. Отчасти это вызвано характером и особенностью решаемых в данной
работе задач, отчасти отсутствием формализованных методик оценки подобных
исследований. Разработка таких методик может значительно упростить анализ
результатов и однозначно определить их корректность и точность.
|

 материалы
материалы