|
Информационный поиск – самостоятельное направление
исследований, изучающее вопросы поиска документов, обработки результатов
поиска, а также целый ряд смежных вопросов: моделирования, классификации,
кластеризации и фильтрации документов, проектирования архитектур поисковых
систем и пользовательских интерфейсов, языки запросов, и т. д.
Документ – это содержательно законченная единица информации,
представленная на каком-либо естественном языке, которая идентифицируется уникальным
образом [13]. Документ - это порция информации, которой оперируют
информационно-поисковые системы.
Информационно-поисковая система – это комплекс программных
средств, обеспечивающих избирательный отбор по заданным признакам документов,
хранимых в оцифрованном представлении.
Способы поиска можно разделить на две большие группы.
1) Библиографический поиск или поиск "по каталогу".
Такой вариант поиска обеспечивает нахождение документов по
их выходным данным, например, по названию документа, по его тематике, по именам
авторов, датам публикаций и т.д. Эти выходные данные составляют реквизиты
документа.
Основой каталога является предварительно заданная модель
представления реквизитов, реализованная в виде базы данных, в соответствии с
которой обеспечивается запись отдельных элементов реквизитов и последующий
поиск по ним.
Основная проблема и недостаток такого варианта поиска - это
необходимость выполнения значительного объема работ по предварительной организации,
наполнению каталога. Как правило, это ручная классификация на основе
привлечения экспертов. Учитывая колоссальные объемы информационных ресурсов,
накопленных к настоящему времени, в совокупности с возрастающими темпами их
роста становится понятным проблематичность структурирования и организации всего
сегодняшнего информационного пространства. Подобный подход позволяет
организовать лишь саму малую толику доступных информационных ресурсов.
2) Тематический поиск или поиск "по тексту".
Этот вариант поиска ориентирован на нахождение документов по
их содержанию. Сюда же относится так называемый полнотекстовый поиск. Общая
схема такого поиска заключается в формулировании некоторого запроса пользователем
относительно содержания документа, и отборе из множества доступных документов,
тех которые удовлетворяют запросу. Такой вариант поиска удобен, прежде всего,
тем, что нет необходимости в предварительном разделении документов по различным
категориям. Особенно это актуально при значительном объеме доступных
документов, высокой динамики их обновления или отсутствии некоторых реквизитов,
такая ситуация характерна для Интернета.
Основная проблема такого поиска – это сложность однозначной
автоматической интерпретации содержания текстов документов и формулировок информационных
потребностей пользователей. Сложность интерпретации затрудняет определение
соответствия рассматриваемого документа информационным потребностям
пользователя [13].
Эти проблемы обусловлены отсутствием какой-либо регулярной
структуры у текстовых документов на естественном языке. Такие информационные ресурсы
принято называть неструктурированными или слабоструктурированными.
Разработка методов анализа слабоструктурированных
информационных ресурсов представляется весьма перспективным и многообещающим
направлением исследований в области информационного поиска.
В соответствии с вышеприведенной классификацией способов
поиска принято выделять два основных класса информационно-поисковых систем:
- Поисковые каталоги
- Поисковые системы
Поисковые каталоги в большей степени ориентированны на
структурную организацию тематических коллекций с удобной системой ссылок и
иерархией документов по тематическим коллекциям. Это позволяет пользователю самостоятельно
находить требуемый документ, просматривая структуру каталога, либо использовать
механизмы поиска ориентированные на данный каталог. В любом случае, организация
информации ее структурирование и предварительное наполнение тематического
каталога является в данном варианте информационно-поисковой системы
первостепенным критерием, определяющим качество и эффективность поиска. Наполнение
тематического каталога документами может выполняться как в ручном, так и в
автоматическом режиме. Однако наиболее качественным все же остается ручной
подбор документов для таких каталогов с привлечением экспертов по конкретным
тематическим разделам или полуавтоматический вариант с предварительным "грубым"
поиском документов и последующей их селекцией.
Поисковые системы ориентированны на поиск
слабоструктурированной информации. Как правило, они используются для поиска
документов в больших и динамичных информационных коллекциях, например, в
Интернете. Особенностью таких коллекций является отсутствие четко выраженной
структурной организации, позволяющей упорядочить и однозначно классифицировать
хранящиеся в них документы по тематической направленности.
В рамках данной работы наибольший интерес представляют именно
поисковые системы, а точнее, используемые в них методы анализа документов.
Процесс поиска текстовой информации, реализуемый типичной
поисковой системой, включает в себя следующие этапы:
- формализация пользователем поискового запроса
(представление пользователем, в том или ином виде, своих информационных
потребностей);
- предварительный отбор документов по формальным признакам
наличия интересующей информации (например, наличие в тексте документа одного из
слов запроса, если запрос формулируется на естественном языке);
- анализ отобранных документов (лингвистический,
статистический);
- оценка соответствия смыслового содержания найденной
информации требованиям поискового запроса (ранжирование).
Специфика поиска в Интернете. Ранние информационно-поисковые системы и методы
поиска разрабатывались и тестировались на относительно небольших, однородных
коллекциях. Современные условия поиска и, соответственно, требования к
информационно-поисковым системам претерпели значительные изменения. Главным
образом, эти условия и требования связаны с развитием Интернета, который имеет
свои специфические черты и особенности [13, 19]. Рассмотрим эти
особенности.
Размер. Одной из главных особенностей
Интернета является огромный объем доступных информационных ресурсов,
продолжающий, к тому же, интенсивно нарастать. По оценкам
специалистов, уже сейчас в Интернете содержится
более миллиарда страниц, общий размер этих страниц оценивается в терабайтах
[41, 95]. В связи с этим возникают высокие требования к
масштабируемости используемых алгоритмов поиска.
Динамика. Высокая степень обновления
информационных ресурсов Интернета. Очень часто появляются новые и удаляются
существующие страницы, меняется их местоположение. Статистика показывает, что
среднее время жизни половины страниц в Интернете не превышает десяти дней,
ежемесячно примерно 40% страниц подвергается изменениям, а объем всей
информации в сети увеличился в два раза за последние два года [41, 87].
Данная особенность значительно затрудняет использование общих статистических
характеристик коллекции.
Взаимосвязи. Одной из особенностей
информационного пространства Интернета является то, что страницы взаимосвязаны
между собой. Эта взаимосвязь реализуется с помощью гиперссылок, что может быть
использовано при реализации некоторых методов поиска.
Свободная публикация. В Интернете
возможно свободное размещение документов и их удаление из коллекции, т.к.
отсутствует централизированное администрирование информационных ресурсов.
Вследствие этого могут быть нарушения целостности отдельных документов
коллекции и связей между ними.
Избыточность. Для Интернета характерна
большая избыточность информационных ресурсов. Очень часто на разных страницах
публикуется несколько копий одного и того же документа или его незначительно
модифицированных версий. Исследования показывают, что около 30% информации в Интернете
- это точные или приблизительные копии других документов [117].
Неконтролируемое качество. Возможность
свободной публикации документов в Интернете, а также отсутствие какой-либо
обязательной проверки их содержания зачастую приводит к появлению
недостоверной и ошибочной информации, содержащей многочисленные орфографические
и грамматические ошибки, опечатки, ошибки, вызванные оцифровкой документов, и
просто некорректные и непроверенные данные.
Пользователи. Интернет объединяет
многочисленные группы совершенно разных по квалификации и подготовке
пользователей. Многие из них не умеют грамотно и эффективно формулировать
запросы. Статистика показывает, что более 60% поисковых запросов в Интернете
состоят из 1-2 слов, для примера, в классических информационно-поисковых
системах эта величина 7-9 слов [42, 85]. Зачастую это приводит к
большому количеству обрабатываемых и анализируемых в результате поиска
документов. Сами результаты поисков в этом случае могут быть весьма далекими от
реальных информационных запросов пользователя, т.к. запрос очень короткий.
Исследования поведения пользователей показали, что многие из
них не готовы к продолжительному ожиданию результатов поиска и анализу результирующего
множества для выявления необходимых документов. 58% пользователей ограничиваются
изучением первого экрана результатов запроса, 67% не пытаются модифицировать
свой первоначальный запрос [85].
При этом критерии качества, используемые в традиционных
системах текстового поиска, становятся неадекватными, например, критерий
полноты поиска, т.е. процент обнаруженных релевантных документов [53].
Доступ. Не всегда возможен доступ к
информационным ресурсам Интернета, т.к. далеко не все сервера работают
круглосуточно в течение всего года.
Многоязычность. Интернет – это
многоязычная информационная среда. Особенно актуальными становятся задачи
мультиязыкового и кросс-языкового поиска. Решение этих задач предполагает
реализацию алгоритмов поиска, независимых от языка представления анализируемых
в процессе поиска документов и языка представления информационных запросов
пользователя.
Требования к системам текстового поиска. Интернет во многом изменил
условия использования систем текстового поиска
и выдвинул к ним новые требования. В сжатом виде главные из этих требований
можно сформулировать следующим образом [13]:
- эффективная обработка очень больших коллекций документов;
- улучшенное отображение смыслового содержания документов и
пользовательских поисковых запросов;
- реализация мультимедийной обработки, т.е. совместной
обработки документов разных форматов и представлений - текстовых документов,
изображений, аудио, видео и др.;
- реализация эффективных методов поиска в потоках документов
(задачи фильтрации).
Отдельно стоит отметить повышение требований к поисковым
системам в отношении так называемого человеческого фактора, определяющего
эффективность взаимодействия человека и поисковой системы. Это касается в
первую очередь проектирования пользовательских интерфейсов и организации работы
человека с поисковой системой. Наметившаяся в последнее время тенденция к
интеллектуализации информационных систем, ориентация систем на человека,
безусловно, затрагивает и системы информационно поиска. Это развитие таких
актуальных направлений исследований как:
- мультиязыковый и кросс-языковый поиск;
- фактографический поиск (реализация поисковой системой
ответов на заданные пользователем вопросы);
- поиск видеоданных (по содержанию видеоданных, поиск
известных объектов, задачи распознавания и т.д.);
- интерактивный поиск (реализация диалога с пользователем во
время поиска, уточнение запросов и т.д.);
- поиск по документу образцу и др.
Вместе с тем существующее положение дел в области
информационного поиска не позволяет пока говорить о безусловной эффективности и
качественности современных поисковых систем. Существует целый ряд противоречий
и проблем, вызванных технической, методологической и организационной сложностью
рассматриваемых задач.
Вместе с тем работы в области информационного поиска успешно
развиваются, накапливается необходимая теоретическая и практическая база. На сегодняшний
день существуют хорошо зарекомендовавшие себя решения в области текстового поиска.
Рассмотрим некоторые из них в ракурсе тематического анализа и идентификации
документов.
1.2.1. Модели поиска
Одним из ключевых понятий, характеризующим выбор того или иного
метода анализа текстовой информации, а также реализацию конкретного варианта
поиска, является модель поиска [26, 46, 116, 118].
Модель поиска – это сочетание следующих составляющих [13]:
- способ представления документов;
- способ представления поисковых запросов;
- вид критерия релевантности документов.
Вариации этих составляющих определяют большое число
всевозможных реализаций систем текстового поиска. Рассмотрим некоторые из них,
наиболее популярные в настоящее время.
Простейшие модели поиска. Это
модели, в которых документ представляется в виде набора ассоциированных с ним
внешних атрибутов. К простейшим моделям поиска относится модель дескрипторного
поиска и модель, основанная на Дублинском ядре.
В простейших системах дескрипторного поиска представление
документа описывается совокупностью слов или словосочетаний лексики предметной
области, которые характеризуют содержание документа. Эти слова и словосочетания
называются дескрипторами. Индексирование документа в таких системах реализуется
назначением для него совокупности дескрипторов. При этом дескрипторы могут
приписываться документу:
- на основе его содержания;
- на основе его названия.
Эти два процесса называются соответственно индексированием
по содержанию и индексированием по заголовкам документов [13].
В некоторых дескрипторных системах индексирование документов
осуществляется вручную экспертами в предметной области системы, в других оно
выполняется автоматически. Представление документа в дескрипторных системах
называется поисковым образом документа.
Дескрипторные системы можно отнести к классу систем,
ориентированных на библиографический поиск или поиск "по каталогу".
Дублинское ядро (Dublin Core) [13, 14, 61] – это набор
элементов метаданных, смысл которых зафиксирован в спецификации определяющего
его стандарта. В терминах значений этих элементов можно описывать содержание
различного рода текстовых документов.
Первоначальная версия Дублинского ядра была предложена в
1995 году на состоявшемся в Дублине (США) симпозиуме, организованном
Online Computer Library Center (OCLC) и National Center for Supercomuting Applications (NCSA)
для описания информационных ресурсов библиотечных систем.
В модели поиска, основанной на Дублинском ядре, представлением k-го документа является
множество пар Dk = {(Nik, Vik)},
где:
Nik – имя i-го элемента метаданных Дублинского ядра в описании содержания k-го документа;
Vik – значение этого элемента метаданных.
Представлением запроса также является множество пар некоторых элементов Дублинского
ядра и их значений Q = {(Nj, Vj)},
где:
Nj – имя j-го элемента метаданных Дублинского ядра в описании пользовательского запроса;
Vj – значение этого элемента метаданных.
Критерий релевантности k – го
документа выглядит следующим образом:
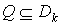 . . |
Модели, основанные на классификаторах.
Это одна из разновидностей простейших моделей поиска. Документ в данной
модели представляется в виде совокупности ассоциированных с ним атрибутов.
Атрибутами являются идентификаторы классов, к которым
относится данный документ. Классы формируют иерархическую структуру классификатора.
Запрос может быть представлен двумя способами:
- Простой вариант – запросом является идентификатор
какого-либо класса из заданного классификатора. Критерий релевантности документа
запросу – класс документа совпадает с классом в представлении запроса или является
его подклассом.
- Сложный вариант – в запросе можно указать несколько
классов классификатора. Критерий релевантности документа запросу – класс документа
совпадает с каким-либо из указанных в запросе классов или является его подклассом.
Модели, основанные на классификаторах, близки к булевским моделям.
Булевские модели. В булевских
моделях поиска пользователь может формулировать запрос в виде булевского
выражения, используя для этого операторы И, ИЛИ, НЕТ. Термы запроса зависят от
конкретного варианта модели поиска. В булевской модели, ориентированной на
поиск "по тексту", термами будут слова, соответственно, критерием релевантности
будет условие вхождения некоторого слова или словосочетания в текст документа.
В булевской модели, ориентированной на поиск по классификаторам, термами
выражения будут идентификаторы классов классификатора. В булевской модели
поиска с использованием Дублинского ядра термом будет значения элементов
метаданных. Документ, имеющий совпадающие значения элементов метаданных со значениями,
заданными в запросе, считается релевантным.
В общем случае критерием релевантности документа запросу в
булевских моделях поиска является истинность булевского выражения, заданного в
запросе.
Одним из несомненных достоинств булевской модели поиска
является простота ее реализации. Главными недостатками считаются:
- отсутствие возможности ранжирования найденные документы
по степени релевантности, поскольку отсутствуют критерии ее оценки.
- сложность использования – далеко не каждый пользователь
может свободно оперировать булевскими операторами при формулировке своих запросов.
Стоит отметить, что предпринимались попытки усложнения
булевской модели поиска для обеспечения возможности ранжирования множества выдаваемых
пользователю документов. А именно, предложено несколько вариантов так
называемых расширенных булевских моделей [116]. В этих моделях вводятся
специальные обобщения булевских операторов, позволяющие придать повышенный вес
документам, в точности удовлетворяющих булевскому выражению запроса, и
пониженный вес – всем остальным документам [13].
Векторные модели. В настоящее
время векторные модели являются самыми распространенными и применяемыми на
практике моделями поиска. Векторные модели, в отличие от булевых, без труда
позволяют ранжировать результирующее множество документов запроса.
Суть таких моделей сводится к представлению документов и
запросов в виде векторов.
Каждому терму ti в документе dj и запросе q
сопоставляется некоторый неотрицательный вес wij (wi для запроса).
Таким образом, каждый документ и запрос может быть представлен в виде k - мерного вектора [21]:
где k - общее количество различных термов во всех документах.
Согласно векторной модели, близость документа di к запросу q оценивается как корреляция между
векторами их описаний. Эта корреляция может быть вычислена, например, как
скалярное произведение соответствующих векторов описаний [8].
Существуют различные подходы к выбору указанных весов. Одним
из самых простых является использование нормализованной частоты данного терма в
документе:
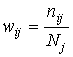 , , |
где
nij – количество повторений данного терма в документе;
Nj – общее количество всех термов в документе.
Более сложные варианты расчета весов учитывают частоту
использования данного терма в других документах коллекции, т. е. учитывают
дискриминационную силу терма [21]. Но эти варианты возможны только при наличии
статистики использования термов в коллекции.
Вариации всевозможных способов назначения весов термов и
оценки меры близости векторов определяют широкий спектр различных модификаций
данной модели поиска.
Вероятностные модели. Впервые идеи
таких моделей были предложены в 1960 году [100]. В их основе лежит
принцип вероятностного ранжирования (Probabilistic Ranking Principle, PRP). Этот принцип
заключается в следующем - наивысшая общая эффективность поиска достигается в случае,
когда результирующие документы ранжируются по убыванию вероятности их
релевантности запросу. Сначала для каждого для каждого документа оценивается
вероятность того, что он релевантен запросу, а затем по этим оценкам
выполняется ранжирование документов.
Существуют различные способы получения этих оценок, а также
дополнительные предположения и гипотезы на основе априорных сведений относительно
документов коллекции, которые и определяют конкретную реализацию вероятностной
модели поиска.
Например, эта оценка может быть вычислена, в соответствии с
теоремой Байеса, по некоторой функции вероятностей вхождения термов данного документа
в релевантные и нерелевантные документы. С помощью запроса определяется
вероятность вхождения заданного терма в релевантные документы, а по полной
коллекции документов определяется вероятность вхождения этого терма в
нерелевантные документы [13].
Сети вывода. Также, как и
вероятностные модели, сети вывода основаны на принципе вероятностного
ранжирования результирующих документов поиска [118, 127]. Главное их отличие от
вероятностных моделей заключается в том, что используется оценка не вероятности
релевантности документа запросу, а вероятности того, что он удовлетворяет
информационным потребностям пользователя.
В рамках данной модели процесс поиска документов описывается
как процесс рассуждений в условиях неопределенности. В процессе такого рассуждения
оценивается вероятность того, что информационные потребности пользователя,
выраженные с помощью одного или нескольких запросов, удовлетворены.
Сеть вывода основана на Байесовской сети, которая включает
узлы четырех видов. Узлами первого вида являются документы коллекции, изученные
пользователем в процессе поиска. Узлами второго вида являются термы, которыми
описывается содержание документов. Узлами третьего вида являются запросы,
состоящие из термов, которыми описывается содержание документов. Узел
четвертого типа в сети только один, и он соответствует информационным
потребностям пользователя, которые не известны поисковой системе. Все узлы
первого и второго вида формируются заранее для заданной коллекции. Узлы
третьего вида и их связи с узлами термов, описывающих документы, и узлом
информационных потребностей формируются для каждого конкретного запроса.
После того, как сеть построена, осуществляется оценка
документов коллекции. Это реализуется распространением по сети оценки
вероятности узла конкретного документа. Результатом распространения является
вычисление вероятности узла информационных потребностей. При этом оценка для
каждого документа строится независимо от оценок других документов, с учетом
матриц описывающих связи между узлами документов и узлами термов, узлами термов
и узлами запросов.
Процесс оценки повторяется для каждого документа, затем они ранжируются на
основе вычисленных оценок вероятности узла информационных потребностей [13].
1.2.2. Методы тематического анализа текстовой информации
Всю совокупность представленных на сегодняшний день методов
тематического анализа текста можно разделить на две большие группы:
- лингвистический анализ;
- статистический анализ.
Первый ориентирован на извлечении смысла текста по его
семантической структуре. Второй – по частотному распределению слов в тексте.
Однако, говорить о принадлежности какого либо из подходов к конкретной группе
можно лишь условно, как правило, в реальных задачах обработки текста приходится
использовать сочетание методик из обеих групп с тем или иным акцентом.
Лингвистический анализ. Лингвистический анализ можно
разделить на четыре взаимодополняющих анализа.
- Лексический анализ. Заключатся в разборе текстовой
информации на отдельные абзацы, предложения, слова, определении национального
языка изложения, типа предложения, выявлении типа лексических выражений (бранных,
жаргонных слов) и т.д. Данный вид анализа не представляет существенной
сложности для реализации.
- Морфологический анализ. Сводится к автоматическому
распознаванию частей речи каждого слова текста (каждому слову ставится в
соответствие лексико-грамматический класс). Часто морфологический анализ
используется в статистических методах анализа при предварительной процедуре
обработки документов - приведение слов к базовой форме.
Морфологический анализ для русского языка можно реализовать практически
со стопроцентной точностью благодаря его развитой морфологии. Для английского
языка алгоритмы, присваивающие каждому слову в тексте наиболее вероятный для
данного слова лексико-грамматический класс (синтаксическую часть речи), работают
с точностью около 90%, что обусловлено лексической многозначностью английского
языка.
- Синтаксический анализ. Заключатся в автоматическом
выделении семантических элементов предложения - именных групп,
терминологических целых, предикативных основ. Это позволяет повысить
интеллектуальность процесса обработки тестовой информации на основе обеспечения
работы с более обобщенными семантическими элементами.
- Семантический анализ. Заключатся в определении
информативности текстовой информации и выделении информационно-логической
основы текста. Проведение автоматизированного семантического анализа текста
предполагает решение задачи выявления и оценки смыслового содержания текста.
Данная задача является трудно формализуемой вследствие необходимости создания
совершенного аппарата экспертной оценки качества информации.
Реализация семантического анализа текстовой информации
предполагает обязательное использование экспертных систем, систем
искусственного интеллекта для выявления смыслового содержания информации. В
настоящее время отсутствуют сложившиеся подходы к реализации задачи
семантического анализа текстовой информации, что во многом обусловлено
исключительной сложностью проблемы и недостаточно полной проработкой научного
направления создания систем искусственного интеллекта.
Статистический анализ. Статистический анализ – это, как
правило, частотный анализ в тех или иных его вариациях. Общая суть такого
анализа заключается в подсчете количества повторений слов в тексте и использовании
результатов подсчета для конкретных целей. Например, вычисление весовых
коэффициентов ключевых слов.
Всевозможные варианты различных реализаций подсчета слов и
последующая обработка результатов подсчета образуют широкий спектр предлагаемых
в данном классе методов и алгоритмов.
Рассмотрим один из наиболее эффективных статистических подходов.
Латентно-семантический анализ. Латентно-семантический
анализ (LSA - Latent Semantic Analysis) - это теория и метод для извлечения
контекстно-зависимых значений слов при помощи статистической обработки больших
наборов текстовых данных [21, 16, 89]. Данный метод анализа используется
не только в области поиска информации [70, 62], но и в задачах фильтрации
и классификации [66].
Основная идея латентно-семантического анализа заключается в
том, что совокупность всех контекстов, в которых встречается и не встречается
данное слово, задает множество обоюдных ограничений, которые позволяют определить
похожесть смысловых значений слов и множеств слов между собой.
Исходной информацией для LSA является матрица термов на документы, которая описывает
используемый для обучения системы набор данных. Элементы этой матрицы содержат
частоты использования каждого терма в каждом документе.
Один из самых распространенных вариантов LSA основан на
использовании разложения исходной матрицы по сингулярным значениям
(SVD - Singular-Value Decomposition). Используя SVD, большая исходная матрица
разлагается во множество из k, обычно от 70 до 200,
ортогональных матриц, линейная комбинация которых является хорошим приближением
исходной матрицы.
Согласно теореме о сингулярном разложении, любая
вещественная прямоугольная матрица X может быть
разложена в произведение трех матриц:
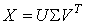 , , |
где матрицы U и V - ортогональные, а
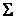 -
диагональная матрица, значения на диагонали которой называются сингулярными значениями матрицы X. -
диагональная матрица, значения на диагонали которой называются сингулярными значениями матрицы X.
Особенность такого разложения в том, что если в
оставить только k
наибольших сингулярных значений, а в матрицах U и V только соответствующие этим
значениям столбцы, то произведение получившихся матриц
lsa,
Ulsa и Vlsa, будет наилучшим приближением исходной матрицы X
матрицей ранга k.
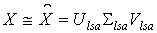 . . |
Идея такого разложения и суть латентно-семантического анализа заключается в том,
что если в качестве X использовалась матрица термов на документ, то матрица
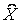 , содержащая только k
первых линейно независимых компонент X, отражает основную структуру ассоциативных
зависимостей, присутствующих в исходной матрице, и в то же время не содержит
шума. , содержащая только k
первых линейно независимых компонент X, отражает основную структуру ассоциативных
зависимостей, присутствующих в исходной матрице, и в то же время не содержит
шума.
Таким образом каждый терм и документ представляются при
помощи векторов в общем, пространстве размерности k
(так называемом пространстве гипотез). Близость между любой комбинацией
термов или документов может быть легко вычислена при помощи скалярного
произведения векторов.
Выбор наилучшей размерности k для
LSA - открытая исследовательская проблема. В идеале, k
должно быть достаточно велико для отображения всей реально существующей
структуры данных, но в то же время достаточно мало, чтобы не захватить
случайные и маловажные зависимости. Если выбранное k
слишком велико, то метод теряет свою эффективность и приближается по
характеристикам к стандартным векторным методам. Слишком маленькое k не
позволяет улавливать различия между похожими словами или
документами. Исследования показывают, что с ростом k
качество сначала возрастает, а потом начинает падать.
Одним из главных недостатков латентно-семантического анализа
является то, что он рассчитан на обработку документов коллекции, т.е. документы
коллекции должны быть доступны. Это в значительной мере ограничивает его
применение.
1.2.4. Поиск по документу-образцу
Одной из частных задач информационного поиска является
задача поиска по документу-образцу. Именно эта задача представляет наибольший
интерес в рамках данной диссертационной работы. Рассмотрим ее подробнее.
Документ-образец выступает в качестве одной из форм
представления информационных потребностей пользователя. Целью поиска является,
обнаружение тематически близких документов. При этом, как правило, речь идет не
о поиске идентичных или синтаксически близких документов, а о поиске документов,
близких по содержанию, близких по смыслу [19].
Самым простым подходом к решению задачи поиска документов по
образцу является использование всех слов документа-образца в качестве запроса.
Однако длина такого запроса может оказаться очень большой, что отрицательно
скажется на качестве поиска, т.к. результатом поиска будут все документы, в
которых присутствовали данные слова, и таких документов может быть очень много.
Это отрицательно скажется как на самой поисковой системе – вычислительные
ресурсы и трафик не безграничны, и система может оказаться перегруженной, так и
на человеке – просмотр и анализ найденных документов может занять значительное
время, редкий пользователь готов к этому [85].
Приемлемым вариантом в данном случае является выделение
тематики документа. Под тематикой понимается множество ключевых слов, описывающих,
с некоторой степенью адекватности, содержание документа. Тематика – это
приближенное представление документа. Для повышения точности и адекватности
описания содержания документа ключевые слова используются с некоторыми весовыми
коэффициентами, которые соотносятся с частотой повторений этих слов в тексте.
Вопросы выделения тематики и вычисления тематической близости документов по их
тематическому представлению во многом и определяют возможность и эффективность
поиска по документу-образцу.
Отметим также, что проведенный анализ существующих к
настоящему времени исследований в области информационного поиска выявил крайне
незначительное число работ по данному направлению.
Несмотря на обилие различных решений, отсутствует четко
проработанная методология поиска по документу-образцу. Существующие подходы не
обеспечивают в полной мере решения этой задачи. В большей степени они являются
смежными по отношению к рассматриваемой задаче.
Так или иначе, существуют определенные наработки по этому
вопросу, в той или иной мере его касающиеся, но при этом отсутствует
достаточное количество специализированных исследований, посвященных решению
именно этого вопроса. Более того, отсутствует четкая формализация постановки
задач такого поиска.
Рассмотрим разработанные к настоящему времени методы и
подходы, используемые при решении задач поиска документов по образцу.
В работе [21] предлагается один из вариантов реализации
поиска документов по образцу, автором предлагается следующая последовательность
действий:
- для каждого документа определяется некоторое
относительно небольшое множество документов, представляющее его аппроксимированное
тематическое окружение;
- построенные тематические окружения анализируются с
целью формирования множеств ключевых слов, характеризующих тематику исходного документа
относительно остальных документов коллекции;
- полученные наборы ключевых слов используются для
дальнейшего вычисления относительных оценок тематического подобия.
В работе приводится также
детальное описание каждого из действий и его конкретная реализация. Не вдаваясь
в подробности, хочется отметить один важный момент, определяющий специфику и
ограничения данного подхода. А именно, реализация такого варианта поиска
предполагает предварительный анализ коллекции доступных документов, что во
многом ограничивает применение данного подхода в коллекциях с высокой динамикой
обновления и большим числом доступных документов. К таким коллекциям относится
Интернет.
Несмотря на особенности среды Интернета, или во многом
благодаря таким особенностям, существуют весьма интересные и оригинальные
варианты реализации поиска документов по образцу в Интернете.
Одним из таких вариантов является использование информации о
структуре ссылок. В общем случае реализация такого варианта предполагает анализ
структуры графа Интернета (вершинами которого выступают страницы, а ребрами -
ссылки). В качестве документа образца выступает некоторая страница, ссылки на
данную страницу и ссылки с нее используются в различных алгоритмах локального
анализа структуры графа Интернета. В работе [88] рассматривается один из
таких алгоритмов – HITS (Hyperlink Induced Topic Search). В рамках этого
алгоритма определяется два класса документов:
- "первоисточник" – документ, на который часто ссылаются в
контексте некоторой тематики (чем чаще ссылаются – тем лучше "первоисточник");
- "посредник" – документ, который ссылается на много "первоисточников"
(чем больше ссылок на первоисточники – тем лучше "посредник").
Алгоритм HITS состоит из двух шагов:
- выбор подмножества Интернет на основе запроса;
- определение лучших "первоисточников" и "посредников"
по результатам анализа этого подмножества [67].
Подмножество строится путем расширения множества найденных
по запросу пользователя страниц за счет добавления всех страниц, связанных с
ними путем, состоящим из одной (иногда двух) ссылок. Далее, для каждого документа
рекурсивно вычисляется его значимость как "первоисточника" и как "посредника"
Суть алгоритма HITS в том, что он пытается выделить "сообщество",
соответствующее тематике запроса, и на основе анализа этого сообщества определить
наиболее авторитетные страницы [21].
Еще одним интересным вариантом решения задачи поиска
документов по образцу является использование документа в дополнение к
традиционному запросу [19]. Часто в процессе поиска возникает необходимость в дополнительной
информации для уточнения результатов поиска, при этом может быть использована
информация из изучаемого в текущий момент документа или уже изученных на данный
момент документов. Запрос в этом случае формируется на основе слов или отдельных
фраз, взятых из этих документов.
В метапоисковой системе IntelliZap как раз реализован
вариант такого уточнения, на основе анализа контекста, выделенного
пользователем текстового фрагмента в исходном документе. Этот контекст может использоваться
затем как на этапе формулировки запросов, так и на этапе ранжирования
результатов, что позволяет значительно повысить точность поиска для очень
коротких (1-2 слова) запросов [64].
Направленность данной работы – это реализация адекватного
отображения информационных потребностей пользователей. Исходя из сформулированных
выше требований к системам текстового поиска - это обеспечение улучшенного
отображения смыслового содержания документов и пользовательских поисковых
запросов, на основе представления пользовательского запроса в виде документа
образца.
Общую схему поиска по документу образцу можно представить в
следующем виде (рис. 1.1).
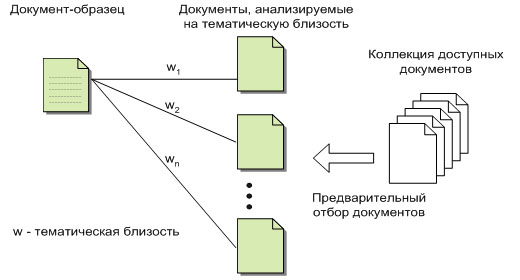 |
| Рис. 1.1. Поиск документов по образцу |
Существует документ-образец и некоторая коллекция доступных
документов. Выполняется предварительный отбор из коллекции документов, и затем
для отобранных документов вычисляется тематическая близость. Вычисленные оценки
тематической близости w1, ..., wn используются при
ранжировании документов по тематической близости к документу образцу.
В данной работе основное внимание уделено вопросам
вычисления тематической близости документов и решению связанных с ними задач.
Вопросы самого поиска, т.е. предварительного отбора документов, в работе не
рассматриваются. Реализация предварительного отбора документов из больших коллекций,
например Интернета, вполне успешно решается существующими методами поиска.
Самый простой вариант предварительного отбора документов из коллекции - по
условию совпадения хотя бы одного слова из документа образца и документа,
принадлежащего коллекции. Более адекватный вариант предварительного отбора – по
тематике документа-образца. Собственно, выделение тематики документов и вычисление
их тематической близости и являются задачами данной диссертационной работы.
Для корректной и адекватной формулировки задач и целей
работы определим используемую терминологию.
В данной работе вопросы поиска документов в явном виде не
рассматриваются. Рассматриваются вопросы анализа документов, а точнее,
тематического анализа текста документов, поэтому корректнее использовать термин
"текст", во всех тех случаях, когда речь идет о вопросах
анализа текста. Там, где необходимо подчеркнуть поисковый аспект, будем
использовать термин "документ".
Текст – это последовательность
предложений, слов, построенная согласно правилам данного языка, данной знаковой
системы и образующая сообщение [25].
Тема текста – некоторое субъективное
представление человека, пользователя поисковой системы, о рассматриваемой в
тексте предметной области, о его основном содержании. Тема текста представляет
собой основу текста, его приближенное представление, которое человек формирует
для себя после чтения текста.
Понятно, что реальная система, задачей которой является
вычисление тематической близости, не может оперировать "некоторыми
субъективными представлениями человека". Необходимо машинное представление темы
текста, коррелирующее с субъективными представлениями пользователя.
Такое машинное представление будем называть тематикой текста.
Тематическая близость – это мера близости текстов по их теме или тематике.
Будем разделять тематическую близость, оцененную
пользователем, и вычисленную на основе тематики.
Оцененная тематическая близость – мера близости
текстов по их теме. Она может быть определена только самим пользователем на
основе его субъективных представлений о теме документов.
Вычисленная тематическая близость -
мера близости текстов по их тематике, полученная в результате вычислений.
Информационный запрос пользователя -
представление информационных потребностей пользователя в форме, воспринимаемой
программным обеспечением систем текстового поиска [13].
Теперь можно сформулировать цель работы, задачи и ограничения.
Цель работы: Метод тематического
анализа текстовой информации для эффективного решения задач поиска документов
по образцу.
Реализация данной цели - это вариант решения одной из
ключевых проблем информационно-поисковых систем - проблемы адекватного
отображения информационных потребностей пользователей.
В данном случае решение этой проблемы основывается на
представлении запроса пользователя в виде документа образца и реализации метода
эффективного анализа тематики документов. В качестве критерия эффективности
выступает точность. Разрабатываемый в работе метод тематического анализа должен
точнее идентифицировать тематику документов.
Задачи работы. Решение задач поиска документов по образцу предполагает
решение двух основных задач:
- выделение тематики документов;
- вычисление тематической близости документов.
Обе эти задачи относятся к задачам классификации – отнесение
документа по его тематическому представлению к некоторому классу и определение
меры близости между различными классами документов.
Сформулируем задачи следующим образом:
- Тематическая классификация текстовой информации.
- Вычисление степени тематической принадлежности текста к образцу.
Ограничения. Сформулируем основные ограничения и допущения для данной работы.
1. Содержание текста – произвольное.
Нет никаких априорных данных о содержании текста и его
структуре. Под структурой текста здесь понимается последовательность текстовых
фрагментов, описывающих отдельные, содержательно законченные элементы текста –
реквизиты, введение, главы, параграфы, заключение и т.д.
2. Коллекция доступных документов не известна.
Существуют ряд методов поиска и методов анализа текста,
опирающиеся на предварительный анализ коллекции доступных документов. Главное
ограничение таких методов заключается в необходимости дополнительной информации
о коллекции и доступ к ее содержимому. В нашей работе будем считать доступными
текст документа-образца и текст документов, анализируемых на тематическую
близость.
3. Размер текста.
Специфика используемого в работе метода тематического
анализа текста, а это преимущественно статистический анализ, предполагает
некоторые ограничения на размер анализируемого текстового фрагмента, т.к.
статистические методы напрямую зависят от объема исследуемой выборки. На данном
этапе работы сформулировать эти ограничения без учета конкретных деталей
реализации метода тематической классификации не представляется возможным. К
данному вопросу вернемся позже, после разработки метода тематической классификации.
В ходе анализа предметной области в данной главе был сделан
общий обзор текущего состояния информационно-поисковых систем, перечислена основная
терминология, решаемые задачи и способы их решения, а также показана специфика
данной области и существующие в ней проблемы. Применительно к существующим в
настоящее время способам и моделям текстового поиска были рассмотрены основные
методы тематического анализа и обработки текстовой информации. Также
рассмотрено современное состояние исследований в области поиска документов по
образцу.
Кроме того, в данной главе были сформулированы цели и задачи
работы, определяющие основное направление и ориентиры диссертационного исследования.
Они заключаются в реализации адекватного представления информационных
потребностей пользователя поисковой системы на основе предъявляемого им текста
образца, выступающего в качестве эталона его информационных потребностей.
Анализ существующих исследований относительно реализации
поиска документов по образцу выявил крайне незначительное число готовых и апробированных
решений в данном области, что во многом связано с отсутствием достаточно
проработанной теории и практики решения задач тематического анализа
неструктурированной естественно-языковой текстовой информации произвольного
содержания. Решение задач тематического анализа востребовано и актуально не
только в области информационно-поисковых систем, но и вообще в системах
обработки и анализа информации. Это широкий спектр различных задач
интеллектуальной обработки информации, в том числе задач извлечения,
идентификации и распознавания смыслового содержания речи. Все это обуславливает
актуальность и значимость исследований в области тематического анализа и
обработки неструктурированной информации.
|

 материалы
материалы