Список всех документов:
Общая характеристика работы
Актуальность темы. Накопленные к настоящему времени колоссальные объемы
информации, в совокупности с непрерывно увеличивающимися темпами ее роста,
определяют актуальность и значимость исследований в области информационного
поиска.
Существует широкий спектр предлагаемых решений и
перспективных направлений исследований в области информационного поиска,
начиная от построения глобальных распределенных информационных структур и
поисковых систем, заканчивая элементарными на первый взгляд вопросами анализа
документов. Все они, безусловно, важны и полезны при решении своих специфических
задач. Тем не менее, именно от методов анализа во многом зависит эффективность
существующих поисковых систем, т.к. они являются основой любой поисковой системы
и во многом определяют возможности и ограничения этих систем.
Помимо этого существует еще один важный фактор,
определяющий, на наш взгляд, эффективность любого информационного поиска – это
человеческий фактор. Именно этот фактор не учитывается в достаточной мере в
современных информационно-поисковых системах. А именно, не учитывается тот
факт, что во многом поиск определяется слабо формализуемыми и нечеткими
условиями, в значительной степени зависящими от опыта и предпочтений самого
человека. Далеко не всегда пользователь информационно-поисковой системы может
четко и однозначно сформулировать именно тот набор ключевых слов, который и
приведет его к искомому результату. Речь идет о варианте поиска на основе
формирования информационных запросов, состоящих из набора ключевых слов и
некоторых управляющих элементов языка запроса.
Сложность формирования информационных запросов может быть обусловлена:
незнанием набора ключевых слов, однозначно определяющих искомый документ;
отсутствием достаточного опыта и квалификации формирования таких запросов;
отсутствием принятой и устоявшейся терминологии в интересующей области. Нередко
человек, осуществляющий поиск, имеет самое приблизительное представление об
интересующей его тематике.
Все это обуславливает актуальность и значимость
исследований, направленных на решение одной из ключевых проблем информационного
поиска – проблемы адекватного отображения информационных потребностей пользователей.
Одним из вариантов решения этой проблемы является поиск
документов по образцу, когда человек задает некоторый документ в качестве
образца, а система, реализующая данный вариант поиска подбирает документы
подобные заданному (подобные по содержанию, тематике).
Анализ существующих исследований, посвященных решению задач
поиска документов по образцу, выявил крайне незначительное число готовых и апробированных
решений, что во многом связано с отсутствием достаточно проработанной теории и
практики решения задач тематического анализа неструктурированной,
естественно-языковой текстовой информации произвольного содержания. Эффективное
решение задач такого анализа, применительно к реализации поиска документов по
образцу, и составляет суть диссертационной работы.
Цель работы – разработка метода тематического анализа
неструктурированной текстовой информации для эффективного решения задач поиска
документов по образцу.
Достижение этой цели основывается на представлении запроса
пользователя в виде документа образца и реализации метода эффективного анализа
тематики документов. В качестве критерия эффективности выступает точность
тематического анализа.
Задачи работы.
Решение задач поиска документов по образцу
предполагает решение двух основных задач:
- выделение тематики документов;
- вычисление тематической близости документов.
Обе эти задачи относятся к задачам классификации – отнесение
документа по его тематическому представлению к некоторому классу и определение
меры близости между различными классами документов.
Задачи формулируются следующим образом:
- Тематическая классификация текстовой информации.
- Вычисление степени тематической принадлежности текста к образцу.
Объект исследования – системы информационного поиска.
В данной работе это одна из разновидностей информационного
поиска – поиск документов по образцу. Это вариант поиска, реализуемый на
основе предварительного выбора пользователем некоторого документа в качестве
образца, по которому затем осуществляется поиск тематически близких ему
документов, с последующим ранжированием результатов поиска по величине
тематической близости к документу образцу.
Предмет исследования – тематический анализ неструктурированной текстовой
информации.
Методы исследования. Для решения поставленных задач использовались
статистический анализ, теория множеств и теория графов.
Положения, выносимые на защиту:
- Графовая модель структурного представления текста
произвольного содержания.
- Метод частотно-контекстной классификации тематики текста.
- Алгоритм вычисления степени тематической принадлежности
текста к образцу.
- Алгоритм поиска значений информационных признаков
тематики текста.
Научная новизна полученных результатов.
Основная научная новизна состоит в том, что разработанная
модель, метод и алгоритмы позволяют эффективнее решать задачи поиска документов
по образцу, в том числе:
- Графовая модель структурного представления текста
произвольного содержания отличается учетом связности и последовательности
текста, что позволяет более полно отразить его семантическое содержание.
- Метод частотно-контекстной классификации тематики
текста отличается дополнением частотно значимых слов контекстно-связанными с
ними словами, что позволяет более точно отобразить тематику текста.
- Алгоритм вычисления степени тематической принадлежности
текста к образцу отличается использованием частотных весов отдельных слов с учетом
их контекстной спецификации, что позволяет более точно вычислить степень
тематической принадлежности произвольного текста к тексту-образцу.
- Алгоритм поиска значений информационных признаков
тематики текста отличается минимизацией разницы экспертных и вычисленных оценок
тематической принадлежности, что позволяет более точно классифицировать тематику
текста и учесть субъективную составляющую при определении степени тематической
принадлежности.
Значимость полученных результатов для теории и практики.
Научная значимость диссертации состоит в развитии методов
тематического анализа и решении задач поиска документов по образцу. Полученные
результаты могут использоваться как при решении конкретных задач поиска
документов по образцу, так и для решения общих задач тематического анализа и
обработки речевых высказываний.
Разработанная модель, метод и алгоритмы позволяют
значительно повысить точность и адекватность тематического анализа. Их
реализация применительно к решению задач поиска документов по образцу позволяет
значительно повысить качество и эффективность такого поиска.
Также в диссертации заложен базис для дальнейшей
теоретической и практической проработки методик экспериментальной оценки
корректности и эффективности методов и алгоритмов тематического анализа.
Практическая значимость диссертации подтверждается актами о
внедрении результатов исследования в Управлении по делам гражданской обороны и
чрезвычайным ситуациям г. Вологды, Администрации г. Вологды, ООО “Премьер-Информ”.
Реализация результатов работы. Представленные в работе результаты были
успешно реализованы в программном исполнении, в виде объектно-ориентированной
библиотеки классов на языке С#.
Данная библиотека нашла свое применение в ряде инженерных
проектов, ориентированных на решение задач документооборота и
информационно-справочного обеспечения.
Апробация работы. Основные положения и отдельные результаты работы
докладывались и обсуждались на следующих конференциях и семинарах:
- на общероссийской научно-технической конференции
“Вузовская наука – региону” (Вологда 2003 г.);
- на международной научно-технической конференции
“Информатизация процессов формирования открытых систем на основе САПР, АСНИ,
СУБД и систем искусственного интеллекта (ИНФОС - 2003)” (Вологда 2003 г.).
Публикации. По теме диссертации опубликовано 6 научных статей.
Структура и объем работы. Диссертация состоит из введения, четырех глав,
заключения, списка литературы, включающего 133 наименования, и одного
приложения. Основная часть работы изложена на 139 страницах машинописного
текста, содержит 15 рисунков, 55 формул и 14 таблиц.
Основное содержание работы
Во введении обоснована актуальность темы диссертационной работы, сформулированы цель и
задачи исследования, приведено краткое содержание работы.
В первой главе проведен анализ текущего состояния информационно-поисковых
систем, современного состояния исследований в области поиска документов по
образцу и существующих методов тематического анализа.
Рассмотрены два основных варианта поиска:
- Библиографический поиск или поиск “по каталогу”.
- Тематический поиск или поиск “по тексту”.
Перечислены их достоинства и недостатки.
В соответствии с ними приведена классификация
информационно-поисковых систем и рассмотрены их особенности.
Выполнен анализ специфики поиска в Интернете. Отмечены
следующие особенности:
- большое количество доступных документов;
- высокая динамика обновления информационных ресурсов;
- взаимосвязь страниц, реализуемая гиперссылками;
- свободная публикация документов и неконтролируемое качество;
- избыточность;
- разнородность пользователей;
- многоязычность документов.
На основе этих особенностей сформулированы основные
требования к современным информационно-поисковым системам и перечислены
перспективные направления исследований.
Рассмотрены основные модели поиска:
- простейшие модели;
- модели, основанные на классификаторах;
- булевские модели;
- векторные модели;
- вероятностные модели;
- сети вывода.
Проведен анализ существующих методов тематического анализа
текстовой информации и выделено две основные группы методов:
- лингвистический анализ;
- статистический анализ.
В группе методов лингвистического анализа рассмотрен
лексический, морфологический, синтаксический и семантический анализ. В группе
статистических методов рассмотрен латентно-семантический анализ.
Проанализировано современное состояние исследований в
области поиска документов по образцу. Общую схему такого поиска можно
представить в следующем виде (рис. 1).
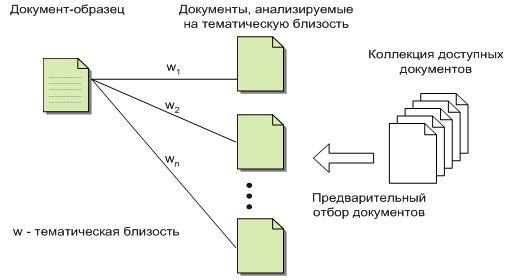 |
| Рис. 1. Поиск документов по образцу |
Существует документ-образец и некоторая коллекция доступных
документов. Выполняется предварительный отбор из коллекции документов, и затем,
для отобранных документов вычисляется тематическая близость. Вычисленные оценки
тематической близости w1, …, wn используются при ранжировании документов по
тематической близости к документу образцу.
Выполнена постановка задач работы и сформулирована ее цель.
Отмечено, что направленность данной работы – это реализация
адекватного отображения информационных потребностей пользователей, на основе
представления пользовательских запросов в виде документа-образца. В данной
работе основное внимание уделено вопросам вычисления тематической близости
документов и решению связанных с ними задач. Вопросы самого поиска, т.е.
предварительного отбора документов, в работе не рассматриваются. Реализация
предварительного отбора документов из больших коллекций, например Интернета,
вполне успешно решается существующими методами поиска.
Во второй главе проведена разработка и теоретическое обоснование модели
структурного представления текстовой информации, а также метода и алгоритмов ее
тематического анализа.
1. Графовая модель структурного представления текста произвольного содержания.
Суть предложенного подхода заключается в моделировании
структуры текста информационным потоком и формировании этим потоком ориентированного
мультиграфа, вершинами которого являются слова, а ребрами – связи между словами
в тексте. Этот мультиграф является информационной структурой текста.
Информационный поток – это детерминированный поток событий,
принадлежащих конечному множеству. Временной интервал между событиями нас не
интересует, интересует только последовательность событий. События – это слова,
а конечное множество – это множество всех уникальных слов, присутствующих в
анализируемом тексте. Информационный поток эквивалентен временному ряду
номинальных (категориальных) величин.
Под информационной структурой понимается совокупность всех
слов и связей между ними. Информационный поток, по сути, моделирует динамику
некоторого процесса, в данном случае текста, а информационная структура
является статическим представлением информационного потока.
Переход к модели структурного представления текста
осуществляется следующим образом.
1) Текст рассматривается в виде информационного
потока, образованного информационными элементами – словами.
Если последовательно брать слова из текста, начиная с самого
первого и кончая последним, то это как раз и будет информационный поток F.
При этом набор всех слов в тексте можно выделить в конечное
множество уникальных информационных элементов: I = {i1, i2, …, in}, где i –
информационный элемент соответствующий уникальному слову текста.
Информационный поток F, описывающий
текст, будет представлен в виде набора этих элементов: F = (ik, …, im),
 , ik – соответствует первому, im
– последнему слову в тексте. , ik – соответствует первому, im
– последнему слову в тексте.
Порядок чередования информационных элементов в F зависит от их последовательности в тексте. Информационные
элементы в потоке могут повторяться. Обязательное условие – однозначное
соответствие информационного элемента слову из текста. Одинаковые слова в
тексте соответствуют одному и тому же информационному элементу.
Пример. Информационный поток соответствующий заданному
фрагменту текста: F = (i3,
i6, i7, i1, i2, i11, i9, i4, i10, i3, i5, i6, i7, i1, i8, i9, i4, i10, i5).
2) Поток формирует структуру.
Если учесть, что слова в тексте повторяются, то,
соответственно, можно допустить, что информационный поток будет многократно
проходить через одни и те же информационные элементы, формируя, таким образом,
связанную информационную структуру текста. Для вышеприведенного примера
информационная структура будет выглядеть следующим образом (рис. 2).
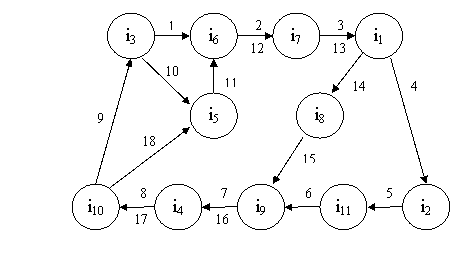 |
| Рис. 2. Структура, формируемая информационным потоком |
Для каждого повторного прохождения потока через одну и ту же
пару информационных элементов, необходимо формировать дополнительные связи -
ребра. Такая структура описывается в виде мультиграфа. Для удобства отображения
мультиграфа (рис. 2) информационный поток индексируется, и каждому ребру
графа, соединяющего пару вершин, приписывается множество индексов
соответствующих прохождению информационного потока через данную пару.
Индексация информационного потока означает, что каждому переходу между двумя
информационными элементами будет поставлен в соответствие индекс, начиная с
единицы, с последовательным его инкрементом. Далее в работе приводятся
дополнительные обозначения и характеристики информационной структуры.
На базе представленной модели выполнена разработка метода и
алгоритмов тематического анализа для решения задач данной работы:
- тематической классификации текстовой информации;
- вычисления степени тематической принадлежности текста к
заданному классу.
2. Метод частотно-контекстной классификации тематики текста.
Предлагаемый подход к тематической классификации текстовой
информации основывается на гипотезе о том, что словарный запас и частоты использования
слов зависят от темы текста.
Тематическая классификация предполагает выделение множества
ключевых слов, определяющих тематику текста. При этом каждому из них
приписывается вес, определяющий значимость данного слова в тематике, т.е.
какие-то ключевые слова играют большую роль в определении тематики, какие-то
меньшую, но именно такая совокупность слов, с такой значимостью каждого из них
в тематике и определяет тематическую направленность.
Такой подход обеспечивает снижение размерности решаемой
задачи за счет перехода от основного текста к его представлению в виде
множества ключевых слов, приближенно описывающих его содержание. Это необходимо,
прежде всего, для последующей тематической идентификации сравниваемых текстов.
Задача классификации в данном случае сводится к задаче отнесения текста к
некоторому тематическому классу, описываемому множеством ключевых слов.
Замечание: тематические классы в этом случае не определены заранее, их
формирование, а также идентификация и отнесение текста к тому или иному классу
происходит в процессе анализа текста.
Ключевые слова определяются по количеству их вхождений в
текст, а именно – частота ключевых слов в тексте выше других слов. В рамках
рассматриваемой модели структурного представления текста это будет означать,
что через данные слова чаще проходит информационный поток, и информационные
элементы, соответствующие этим словам, имеют большее количество связей с
другими информационными элементами.
Проблема заключается в определении порога
(автоматизированном, машинном определении), который отделяет ключевые слова от
всех остальных.
Автором выдвигается гипотеза о том, что корректное и
адекватное машинное представление тематики текста должно включать в себя не
только ключевые слова, но и контекст этих слов, т.к. смысл любого слова
определяется исключительно в контексте тех слов, которые употреблялись вместе с
ним, близко, рядом по тексту. И сами по себе ключевые слова в отрыве от их
контекста не отражают в полной мере тематическую направленность текста.
Существующие исследования в психолингвистике подтверждают данный тезис.
Необходимость дополнения ключевых слов контекстом
определяется также соображениями практического характера. Суть этих соображений
заключается в следующем.
Особенности частотного распределения слов в тексте могут
значительно затруднить выбор пороговой величины и снизить качество последующего
анализа документов на тематическую близость. Например, ситуация частотного
выброса одного из слов. Непонятно при этом, какой необходимо устанавливать
порог отсева, если частота повторений одного слова значительно превосходит все
остальные, а все остальные при этом имеют одинаковую частоту. Либо устанавливать
порог для выделения одного ключевого слова, или опускать порог и брать все
слова текста в качестве тематики. И тот, и другой вариант неприемлемы, в одном
случае тематика текста будет представлена в виде одного слова, в другом –
тематикой будут все слова. Организация последующего поиска тематически близких
документов (текстов), на основе множества ключевых слов, выступающих в качестве
поискового запроса, представляется в этом случае весьма проблематичной. Если поисковый
запрос представлен одним словом – результат поиска может дать незначительное
число тематически близких документов, если поисковый запрос представлен всеми
словами документа, то результат поиска может дать слишком много тематически
“далеких” документов.
Дополнение ключевых слов контекстом в этом случае является
вполне разумным и приемлемым вариантом решения данной проблемы.
Общая последовательность метода выглядит следующим образом.
- Моделирование текста и формирование его
информационной структуры.
- Выделение множества всех информационных элементов,
ранжированных по их числу повторений в тексте.
- Выделение множества ключевых элементов Sp.
Из множества всех информационных элементов (полученных на
предыдущем этапе) берем n первых (n
определяется на основе пороговой величины), которые будут первичным множеством
ключевых элементов Sp = {k1i1,
k2i2, …, knin},
весовые коэффициенты k1, k2, …, kn
определяют значимость того или иного
информационного элемента в данной тематике.
- Формирование уточняющего множества Ss,
на основе контекстного анализа информационных элементов множества Sp.
Контекстный анализ основан на анализе окрестностей информационных элементов, по ранее
сформированной информационной структуре, подробно он рассматривается в тексте диссертации.
- Получение общего множество ключевых элементов,
определяющее тематику текста: S = Sp
+ Ss.
Результатом метода является множество S = {k1i1,
k2i2, …, knin}.
3. Алгоритм вычисления степени тематической принадлежности текста к образцу.
Есть текст-образец, и есть некоторый произвольный текст,
необходимо количественно оценить, насколько близка тематика произвольного
текста к тематике заданного текста образца, т.е. вычислить степень тематической
принадлежности текста к образцу. Далее для краткости будем использовать термин
тематическая близость.
И произвольный текст, и текст-образец могут быть
представлены в виде тематических классов, метод частотно-контекстной
классификации, позволяет это сделать. Необходимо вычислить тематическую
близость двух произвольных тематических классов, заданных множествами ключевых
элементов (слов).
Пусть S = {k1i1, k2i2, …, knin} – множество ключевых элементов
текста образца; Sf = {kf1i1, kf2i2, …, kfnin}
– множество ключевых элементов некоторого найденного в результате поиска текста
(документа найденного информационно-поисковой системой), который нам необходимо
проанализировать на тематическую близость по отношению к тексту образцу.
Тематическую близость  по каждому из информационных элементов
будем вычислять как: по каждому из информационных элементов
будем вычислять как:
Коэффициент общей тематической близости для всего текста,
будет вычисляться как сумма всех  : :
 . . |
Вычисляя 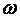 для каждого найденного текста
(документа) можно выполнить ранжирование этих документов по тематической
близости. для каждого найденного текста
(документа) можно выполнить ранжирование этих документов по тематической
близости.
Учет контекста. Рассмотренный выше
способ расчета тематической близости необходимо дополнить одним важным
соображением. Как уже было сказано выше, значение слова определяется по его
контексту, по тем словам, которые употреблялись вместе с ним. Особенно это
значимо при вычислении тематической близости. Одно и то же слово,
присутствующее в S и Sf,
может нести в себе совершенно разный смысловой оттенок, смысловую нагрузку. И
простого сравнения весовых коэффициентов недостаточно для корректного
вычисления тематической близости, необходимо еще учитывать контекст слов.
В работе предлагается способ учета контекста на базе самого
текста (документа), без дополнительного анализа документов коллекции. Этот способ
реализован на основе контекстного анализа, подробно он рассмотрен в
диссертации.
4. Алгоритм поиска значений информационных признаков тематики текста.
Вычисление тематической близости текстов предполагает
предварительное выделение ключевых слов этих текстов с некоторыми весами и
последующее их сравнение между собой, т.е. вычисление меры их близости. Сами
тексты при этом не сравниваются, речь идет о переносе оценки близости ключевых
слов на весь текст. Очевидна при этом условность такой оценки и значительное
влияние на результат параметров, используемых при выделении тематики. Кроме
того, необходимо отметить исключительную субъективность самого понятия
тематической близости текстов. Это понятие предполагает значительную роль и
участие человека в оценке тематической близости текстов. У человека есть
некоторые ожидания относительно искомых текстов (документов) и их соответствия
тексту (документу) образцу. Предполагаемая человеком оценка может в
значительной мере отличаться от вычисленной оценки приближенного представления
текстов.
Для корректного вычисления тематической близости необходимо
учитывать как параметры, использованные при выделении тематики, так и
субъективную составляющую. Это предполагает реализацию некоторого варианта
предварительной настройки и поиска оптимальных параметров тематики текста,
названных информационными признаками.
Реализуется такой поиск минимизацией разницы экспертных и
вычисленных оценок тематической близости текстов. Подробно алгоритм
рассматривается в тексте диссертационной работы.
Третья глава посвящена практической реализация модели структурного
представления и метода тематического анализа текста. В ней рассмотрены вопросы
организации поиска, на основе предложенных в работе результатов, а также
приведена их конкретная реализация в виде объектно-ориентированного
программного кода на языке C#.
Рассмотрен вариант тематической классификации нескольких
текстов на основе обобщения множества тематически близких документов. Данный
вариант реализуется конкатенацией текстовых фрагментов, т.е. один текст
добавляется к другому, и информационный поток описывает уже не один, а
несколько текстов. Тематическое обобщение множества документов в единую
информационную структуру позволяет организовать поиск на основе нескольких, уже
найденных к этому моменту, документов. Документом-образцом в этом случае
выступает не один, а несколько документов.
Обобщенное множество текстов также позволяет организовать
всю терминологическую базу найденных документов в связанную структуру. И эту
структуру можно использовать для расширения произвольно заданного набора
ключевых слов.
Рассмотрен способ организации поиска документов по образцу
на базе представленных в работе результатов. Поиск планируется выполнять с
помощью стандартных, отработанных методов, реализуемых в настоящее время
поисковыми системами. В частности, это вариант векторной модели поиска или
взвешенной булевой. Такой вариант поиска предполагает формирование поискового
запроса, состоящего из множества ключевых слов. Это множество получается с
помощью приведенного в работе метода частотно-контекстной классификации. На его
основе формируется поисковый запрос, который отрабатывает поисковая система.
Это может быть уже существующая поисковая система, с которой интегрируется
предложенный метод и алгоритмы, или уникальная реализация под конкретную
задачу. По результату поиска получается множество документов. Используя
алгоритм вычисления степени тематической принадлежности текста к образцу, эти
документы анализируются, вычисляется их тематическая близость по отношению к
документу образцу, и затем они ранжируются по величине близости.
Рассмотрены этапы предварительной обработки текста, которая
включает в себя.
1) Лексический анализ. На этом этапе выделяются отдельные
слова из текста.
2) Исключение часто используемых слов. В любом тексте
существует большое количество слов, используемых в качестве союзов, предлогов,
местоимений и т.д., так называемые “стоп-слова”, (“stop-words”). Такие слова традиционно исключаются поисковыми
системами при анализе документов.
Как правило, эти слова не определяют тематику текста, но при
этом являются частотно-значимыми. Это затрудняет выделение тематики на основе
анализа статистики слов. Такие слова необходимо исключать из текста.
Данная процедура выполняется на основе предварительно
составленного списка наиболее часто встречающихся слов в документах – списка
игнорируемых слов.
3) Морфологический анализ. На этом этапе слова приводятся к
базовой форме. Например, слова: компьютеры, компьютером, компьютера, компьютеру
и т.д., заменяются на слово компьютер.
После предварительной подготовки текста, выполняется его
обработка и тематический анализ по приведенным ранее модели, методу и
алгоритмам.
Также в данной главе приведены фрагменты программного кода,
демонстрирующие конкретные аспекты практической реализации представленных в
работе результатов.
В четвертой главе представлены результаты экспериментальных исследований
разработанных в диссертационной работе метода и алгоритмов тематического
анализа на заданной коллекции тестовых документов.
1) Метод частотно-контекстной классификации тематики текста.
Само понятие тематики заведомо предполагает субъективный
характер оценки получаемых результатов. Только человек может оценить, насколько
тематика (машинное представление темы текста) адекватна субъективному
представлению пользователя о содержании текста. Также необходимо отметить
сильную зависимость от текста, адекватность и корректность выделения тематики
можно оценить только по реальному тексту. Все это определяет характер и особенности
проведения экспериментальных исследований метода частотно-контекстной
классификации тематики текста. Единственно возможный способ его прямой оценки –
это приведение примеров выделения тематики для некоторых заданных текстов. Эти
примеры представлены в диссертационной работе.
Помимо этого, существует возможность косвенной оценки метода
на основе экспериментальных исследований алгоритма вычисления степени
тематической принадлежности текста к образцу, т.к. корректность вычисления
тематической близости напрямую зависит от корректности выделения тематики. В
диссертационной работе разработан один из вариантов такой оценки, его описание
приводится ниже.
2) Алгоритм вычисления степени тематической принадлежности
текста к образцу.
Корректность и адекватность данного алгоритма, а вместе с
ним метода частотно-контекстной классификации тематики текста можно оценить по
сходимости следующего условия:
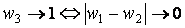 , ,
где w1,
w2, w3 –
степени тематической близости текстов Т1, T2,
T3 (рис. 3).
 |
| Рис. 3. Соответствие текстов и коэффициентов тематической близости |
Смысл этого условия заключается в том, что тематически
близкие тексты T3 и T2,
будут одинаково тематически близки по отношению к T1.
Точнее сказать, чем выше тематическая близость текстов T3
и T2, тем меньше разница тематической
близости этих текстов по отношению к T1.
Единица в нашем случае соответствует максимальному значению тематической
близости. На рис. 4 приведен график, соответствующий данному условию.
 |
| Рис. 4. Идеальный график распределения величин тематической близости |
Оценка сходимости условия выполнена путем вычисления w1, w2, w3 для множества комбинации из трех документов.
Результат распределения вычисленных значений представлен на рис. 5.
 |
| Рис. 5. Реальный график распределения величин тематической близости |
Как видно из полученных результатов, указанное условие
действительно выполняется.
3) Алгоритм поиска значений информационных признаков
тематики текста.
Проверка данного алгоритма осуществлена путем проведения
нескольких серий экспериментов. Для каждой серии были заданы экспертные оценки
тематической близости некоторых текстов, по этим оценкам был осуществлен подбор
оптимальных параметров и последующее вычисление тематической близости текстов.
Ошибка вычислений составила не более 8%.
4) Сравнение точности вычисления тематической близости.
Помимо проверки корректности и адекватности метода и
алгоритмов, выполнена оценка их эффективности в сравнении с уже существующими
подходами. Точность вычислений, предложенным в работе алгоритмом вычисления
степени тематической принадлежности к образцу, сравнивалась с точностью
вычислений полученных традиционным (для большинства информационно-поисковых
систем) способом расчета меры близости векторов по косинусу угла, определяемого
через скалярное произведение векторов:
 , , |
где 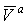 и
и  - сравниваемые вектора. - сравниваемые вектора.
Оценка показала, что точность вычислений, полученных с
помощью представленного в работе алгоритма вычисления степени тематической
принадлежности текста к образцу, выше точности вычислений полученных с помощью
косинусной меры, приблизительно на 30%.
Экспериментальные исследования проведены на заданной
коллекции текстов, содержание текстов приводится в приложении диссертации.
В заключении
подведены итоги проделанной работы, сформулированы основные результаты и
направления дальнейших исследований.
Основные результаты работы
- Графовая модель структурного представления текста
произвольного содержания, позволяющая отобразить семантическую связность и
последовательность текста в виде структуры.
- Метод частотно-контекстной классификации тематики
текста, позволяющий выделять тематику текста в виде множества ключевых слов с
весами, характеризующими значимость данных слов в тематике.
- Алгоритм вычисления степени тематической
принадлежности текста к образцу, позволяющий получать количественную оценку
тематической близости текстов.
- Алгоритм поиска значений информационных признаков
тематики текста, позволяющий учесть субъективный характер оценки тематической
близости текстов, и настроить систему, реализующую поиск документов по образцу
под конкретного пользователя.
Список опубликованных работ по теме диссертации
- Чугреев В.Л., Моделирование
систем искусственного интеллекта. // Перспективные технологии автоматизации:
Тезисы докладов международной электронной научно-технической конференции. –
Вологда: ВоГТУ, 1999. - стр. 151-152.
- Чугреев В.Л., Моделирование
систем искусственного интеллекта. // Молодые исследователи – региону: Тезисы
докладов Второй областной межвузовской студенческой научной конференции. –
Вологда: ВоГТУ, 2000. – стр. 5-6.
- Чугреев В.Л., Расширение
искусственных нейронных сетей применительно к задачам прогнозирования. //
Молодые исследователи – региону: Материалы межрегиональной научной конференции
студентов и аспирантов. – Вологда: ВоГТУ, 2002. – стр. 231-232.
- Чугреев В.Л., Яковлев С.А.,
Выделение критериев поиска текста на основе подобия значимых документов. //
ВУЗОВСКАЯ НАУКА – РЕГИОНУ: Материалы 1-й Общероссийской нучн.-техн. конф. –
Вологда: ВоГТУ, 2003. – стр. 200-202.
- Чугреев В.Л., Яковлев С.А.,
Анализ структуры текста и прогнозирование нечисловых величин. // ВУЗОВСКАЯ
НАУКА – РЕГИОНУ: Материалы 1-й Общероссийской нучн.-техн. конф. – Вологда:
ВоГТУ, 2003. – стр. 202-204.
- Чугреев В.Л., Яковлев С.А., Анализ текста, применительно
к решению задач поиска документов по образцу. // Информатизация процессов
формирования открытых систем на основе САПР, АСНИ, СУБД и систем искусственного
интеллекта (ИНФОС - 2003): Материалы 2-й Межд. науч.-техн. конф. – Вологда:
ВоГТУ, 2003. – стр. 49-52.
|

 материалы
материалы 
 ,
,