|
Целью данной главы является демонстрация возможного применения описанной системы распознавания образов в различных предметных областях. Уделим внимание построению объектных моделей предметных областей, а также полученным результатам.
Для проверки результатов функционирования системы распознавания образов будем использовать тестовую выборку - множество объектов, о которых, также как и о объектах обучающей выборки, известно к какому из классов они относятся. Будем использовать непересекающиеся тестовую и обучающую выборки.
Полученные на тестовой выборке результаты будем оценивать следующими коэффициентами:
Коэффициент точности отнесения к данному классу - вычисляется как:
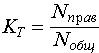
где: 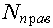 - количество объектов тестовой выборки фактически относящихся к данному классу и распознанных как объекты данного класса; - количество объектов тестовой выборки фактически относящихся к данному классу и распознанных как объекты данного класса; 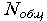 - общее количество объектов тестовой выборки фактически относящихся к данному классу. Значение коэффициента точности будет колебаться около вероятности того, что объект, фактически относящийся к данному классу будет распознан как объект данного класса. Например, коэффициент точности отнесения к классу - общее количество объектов тестовой выборки фактически относящихся к данному классу. Значение коэффициента точности будет колебаться около вероятности того, что объект, фактически относящийся к данному классу будет распознан как объект данного класса. Например, коэффициент точности отнесения к классу 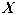 равный 3/4 показывает, что если на вход системы подать объект (его описание), фактически относящийся к классу равный 3/4 показывает, что если на вход системы подать объект (его описание), фактически относящийся к классу 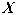 , то вероятность того, что он будет распознан как объект этого класса близка к 3/4 т. е. ошибка в одном случае из четырех. , то вероятность того, что он будет распознан как объект этого класса близка к 3/4 т. е. ошибка в одном случае из четырех.
Коэффициент доверия отнесения к данному классу - вычисляется как:
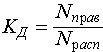
где: 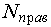 - количество объектов тестовой выборки фактически относящихся к данному классу и распознанных как объекты данного класса; - количество объектов тестовой выборки фактически относящихся к данному классу и распознанных как объекты данного класса; 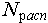 - общее количество объектов тестовой выборки распознанных как объекты данного класса. Значение коэффициента доверия будет колебаться около вероятности того, что объект, распознанный как объект данного класса, фактически является объектом данного класса. Например, коэффициент доверия отнесения к классу - общее количество объектов тестовой выборки распознанных как объекты данного класса. Значение коэффициента доверия будет колебаться около вероятности того, что объект, распознанный как объект данного класса, фактически является объектом данного класса. Например, коэффициент доверия отнесения к классу 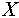 равный 4/5 показывает, что если некоторый объект (его описание), поступивший на вход системы, был распознан как объект класса равный 4/5 показывает, что если некоторый объект (его описание), поступивший на вход системы, был распознан как объект класса 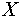 , то вероятность того, что он действительно является объектом этого класса близка к 4/5 т. е. ошибка в одном случае из пяти. , то вероятность того, что он действительно является объектом этого класса близка к 4/5 т. е. ошибка в одном случае из пяти.
Коэффициент качества распознавания - вычисляется как:
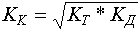
Коэффициент качества распознавания - это сводный коэффициент, позволяющий объединить в одном показателе коэффициенты точности и доверия.
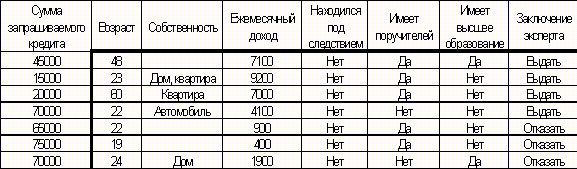
Выдаче кредита кому-либо предшествует заключением о том, что данный заемщик в состоянии вернуть в срок занимаемую сумму. Заключение выдается соответствующим экспертом, основывающимся на некоторых сведениях о заемщике. Роль эксперта, таки образом, заключается в том, чтобы, основываясь на имеющихся данных отнести заемщика либо к классу платежеспособных - выдать кредит; либо к классу неплатежеспособных - отказать в выдаче кредита. Пусть, например имеются следующие данные о заемщиках и о заключении эксперта:
Таблица 1. Пример сведений о заемщиках
Построим систему распознавания образов, способную на основе подобных данных делать выводы о платежеспособности заемщика.
Для начала построим объектную данной предметной области.
Объект "Заемщик". Тип объекта: не-контейнер. Признаки объекта:
"Возраст" - простой признак, может принимать значение в интервале от 20 до 100 (допустим, что заемщиков вне этого возрастного интервала нет). "Собственность" - сложный признак. Видами собственности, в рамках нашего примера, могут быть дом, квартира, автомобиль. Поскольку заемщик может владеть сразу несколькими видами собственности (из предложенных), то данный признак будет иметь три состояния ("дом", "квартира", "автомобиль") и может находиться как в нескольких из них, так и ни в одном. "Доход" - простой признак. Чтобы не ориентироваться на абсолютные значения запрашиваемого кредита и ежемесячного дохода заемщика, будем брать значением этого признака отношение ежемесячного дохода заемщика к запрашиваемому кредиту, в процентах. Таким образом, признак "доход" может принимать значения в интервале от 0 до 100 процентов от запрашиваемого кредита (Допустим, в рамках данного примера, что заемщик не обращается за кредитом, меньшим его ежемесячного дохода). "Находился под следствием" - простой признак, может принимать значение либо "Да", либо "Нет". Имеет соответственно два состояния. "Имеет поручителей" - простой признак, может принимать значение либо "Да", либо "Нет". Имеет соответственно два состояния. "Имеет высшее образование" - простой признак, может принимать значение либо "Да", либо "Нет". Имеет соответственно два состояния.
Объект "Заемщик" может быть двух классов - "платежеспособный" и "НЕплатежеспособный".
На основе описанной объектной модели была написана программа CHCK_CRD, способная проводить классификацию заемщиков, исходный код программы приведен в приложении 6.2. Использованные обучающие и тестовые выборки приведены в приложении 1.
Таблица 2. Полученные результаты. Класс 1 – заемщик платежеспособный, Класс 2 - заемщик не платежеспособный.
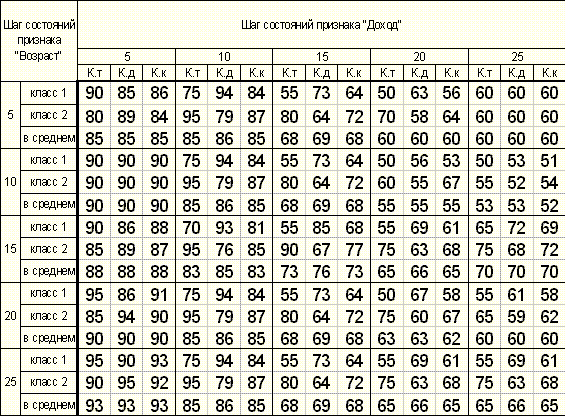
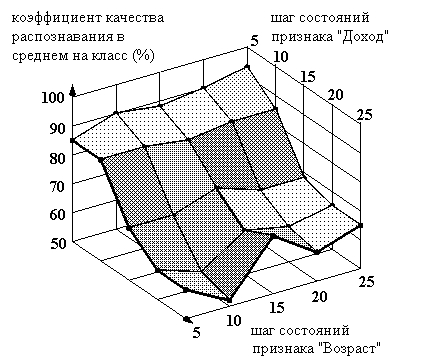
Рисунок 12. Зависимость коэффициента качества распознавания от шагов состояний признаков "Доход" и "Возраст" объекта "Заемщик"
Таким образом, видно, что наибольшего качества распознавания в данной предметной области при данной объектной модели и на данных обучающей и тестовой выборкок можно достичь при шаге состояний признака "Возраст" 25 лет и при шаге состояний признака "Доход" в 5 %.
Оценка стоимости подержанных автомобилей производится с помощью учета ряда факторов, учитывающих возраст и состояние автомобиля. Пусть, например, сведения о оцененных автомобилях представлены в следующей форме:
Таблица 3. Пример сведений о автомобилях
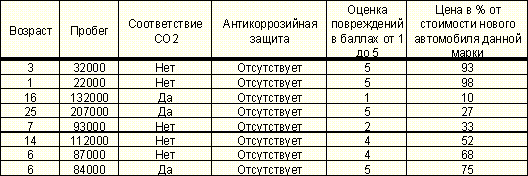
Можно, разбив цену автомобиля на ряд интервалов-классов, отнести каждый конкретный автомобиль к какому-либо из классов цены. Построим систему распознавания образов, способную на основе данных о автомобиле отнести его к классу цен - т. е. указать в каком примерно интервале находится цена данного автомобиля.
Для начала, построим объектную модель предметной области.
Объект "Автомобиль". Тип объекта: не-контейнер. Признаки объекта:
"Возраст" - простой признак. Может принимать значение в интервале от 0 до 20 лет. Будем в рамках данного примера считать, что все автомобили входят в данный возрастной диапазон. "Пробег" - простой признак. Может принимать значение в интервале, в рамках данного примера, от 10 до 200 тысяч километров. Будем в рамках данного примера считать, что пробег всех автомобилей входит в данный диапазон.
"Соответствие СО2" - простой признак, может принимать значение либо "Да", либо "Нет". Имеет соответственно два состояния. "Наличие антикоррозийной защиты" - простой признак, может принимать значение либо "Да", либо "Нет". Имеет соответственно два состояния. "Повреждения" - простой признак, может принимать одно из значений, соответствующих целым числам от 1 до 5 включительно. Имеет соответственно пять состояний.
Была написана программа CAR_PAY (исходный код в приложении 6.3), делающая на основе обучающей выборки выводы о том, к какому из классов цен относится каждый из автомобилей тестовой выборки. Состав обучающей и тестовой выборок приведен в приложении 2.
Покажем некоторые из полученных результатов.
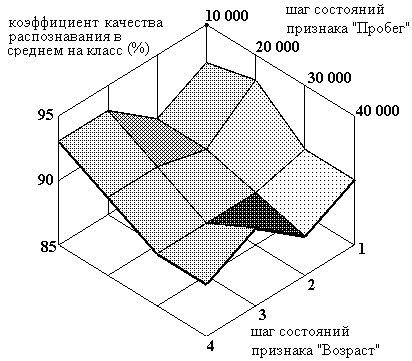
Рисунок 13. Зависимость качества распознавания от шагов состояний признаков "Возраст" и "Пробег" при количестве классов равном двум
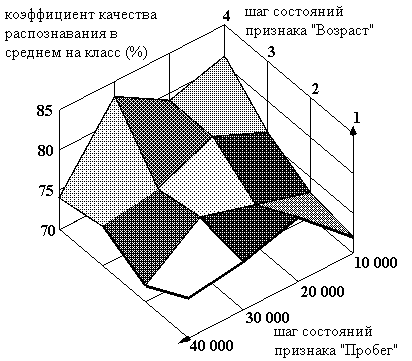
Рисунок 14. Зависимость качества распознавания от шагов состояний признаков "Возраст" и "Пробег" при количестве классов равном пяти
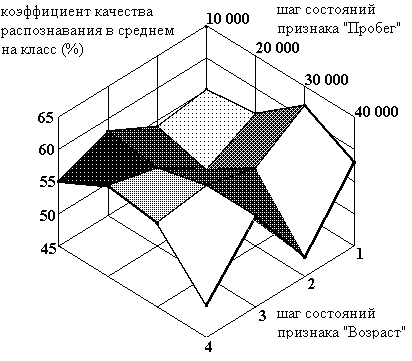
Рисунок 15. Зависимость качества распознавания от шагов состояний признаков "Возраст" и "Пробег" при количестве классов равном десяти
Таблица 4. Зависимость качества распознавания от шагов состояний признаков "Возраст" и "Пробег" при количестве классов равном двум
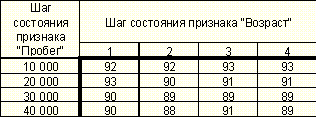
Таблица 5. Зависимость качества распознавания от шагов состояний признаков "Возраст" и "Пробег" при количестве классов равном пяти
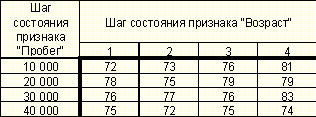
Таблица 6. Зависимость качества распознавания от шагов состояний признаков "Возраст" и "Пробег" при количестве классов равном десяти
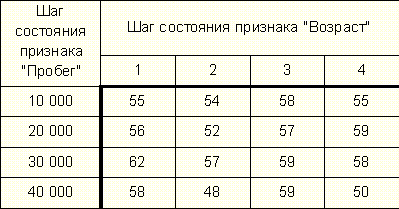
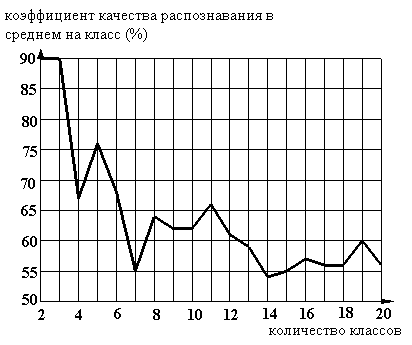
Рисунок 16. Зависимость качества распознавания от количества классов. Шаг признака "Возраст" равен 1; признака "Пробег" равен 30000.
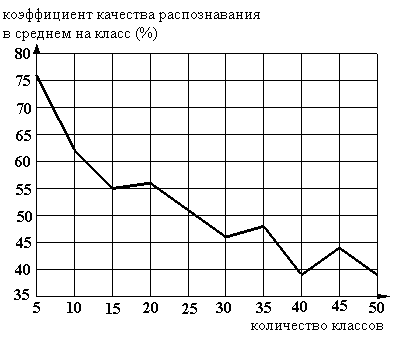
Рисунок 17. Зависимость качества распознавания от количества классов. Шаг признака "Возраст" равен 1; признака "Пробег" равен 30000.
Таком образом, видно, что при росте количества классов - требуемой точности указания цены автомобиля, снижается качество распознавания. Оптимальным вариантом можно признать вариант с десятью классами - т. е. цену автомобиля можно отнести к одному из интервалов: 0-10%; 10-20%; 20-30%... 80-90%, 90-100%. Как видно из приведенных выше данных в этом случае коэффициент качества равен 62% т. е. в среднем в 62 случае из 100 можно доверять заключению системы.
Возможно, более высокого качества распознавания можно добиться выбрав другую объектную модель предметной области. Например, если бы мы указывали в составе сведений о автомобиле каждую из обнаруженных неисправностей, то можно было бы построить, например, следующие объектные модели:
- 1. Выделить все неисправности в один отдельный сложный признак, состояния которого есть наличие той или иной неисправности. Например, состояниями могут быть: "Разбиты фары", "Неисправны тормоза", "Течет маслопровод" и т. п.
- 2. Выделить каждый вид неисправности в отдельный простой признак, способный находиться в одном из двух состояний: "Данная неисправность отсутствует", "Данная неисправность наличествует". Тогда данные о автомобилях выглядели бы, например, следующим образом:
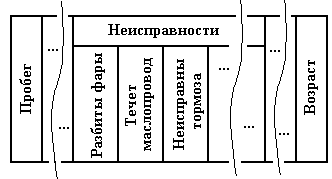
Рисунок 18. Пример сведений о автомобиле
- 3. Предыдущую объектную модель можно расширить, если допустить, что каждая конкретная неисправность может находиться в состояниях не только, описывающих наличие неисправности, но и в состояниях, описывающих особенности конкретной неисправности, например, ее размер.
- 4. Указанные выше модели обладают тем недостатком, что в состав сведений о неисправностях автомобиля необходимо включать все учитываемые неисправности, пусть и находящиеся в состоянии "Данная неисправность отсутствует". Это может значительно увеличить объем сведений, необходимых для учета, повысить требования к объему машинной памяти, увеличить продолжительность расчетов. Рассмотрим объектную модель, позволяющую включать в состав сведений о автомобилях лишь описание тех неисправностей, которые наличествуют. Представим признак "Неисправность" в виде непозиционного контейнера, являющегося сложным признаком объекта "Автомобиль". Элементы контейнера - конкретные неисправности. Каждая неисправность помечена признаком-маркером, позволяющим выделять однотипные неисправности у разных автомобилей. Признак-маркер - это простой признак, имеющий по одному состоянию на каждый тип неисправности, и способный находиться только в одном из состояний.
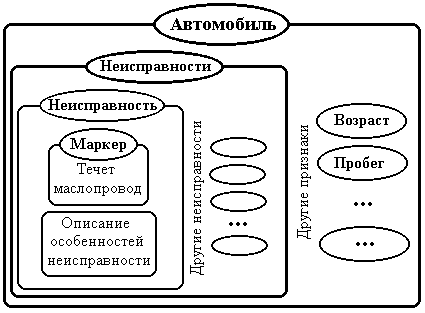
Рисунок 19. Пример объектной модели
Перечень возможных состояний элементов контейнера ограничим теми состояниями, в которых признак-маркер принадлежит к признакам, описывающим данное состояние. Это позволит при сравнении автомобилей сопоставлять однотипные неисправности, а не сравнивать, например, износ покрышек одного автомобиля с поцарапанной дверью другого.
Таким образом видно, что для одной и той же предметной области можно построить различные объектные модели отличающиеся, помимо прочего, той или иной степенью адекватности.
В работе [14] приводится описание экспертной системы, выступающей в роли эксперта-консультанта, дающего на основе ряда сведений о фондовой бирже заключения о ожидаемом поведении уровня цен. Пусть, например, имеются следующие данные:
Таблица 7. Пример сведений о фондовой бирже
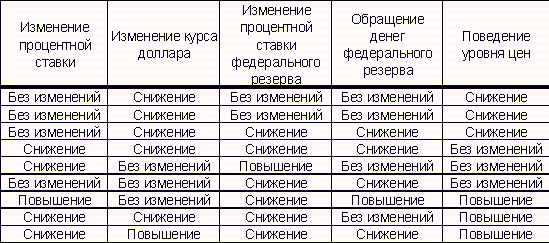
В [14] построению экспертной системы предшествовал этап анализа, в котором, на основе сведений о функционировании фондовой биржи и поведения уровня цен, был составлен набор правил, позволяющий судить о ожидаемом уровне цен, в зависимости от ситуации.
Построим систему распознавания образов, способную на основе данных, подобных данным в приведенной выше таблице, делать выводы о поведении уровня цен. Заметим, что в приведенных данных прямо не говорится, какие именно показатели должны иметь какое именно значение, чтобы уровень цен, например, снижался.
Для начала построим объектную модель предметной области.
Объект: "Ситуация на бирже". Тип объекта: не-контейнер. Признаки:
"Ставка" - изменение процентной ставки. Простой признак. Может находиться в одном из трех состояний - "Снижение", "Без изменений", "Повышение" "Курс" - изменение курса доллара. Простой признак. Может находиться в одном из трех состояний - "Снижение", "Без изменений", "Повышение" "Федеральная ставка" - изменение процентной ставки федерального резерва. Простой признак. Может находиться в одном из трех состояний - "Снижение", "Без изменений", "Повышение" "Обращение резерва" - обращение денег федерального резерва. Простой признак. Может находиться в одном из трех состояний - "Снижение", "Без изменений", "Повышение"
Выделим три класса объектов: "Уровень цен снижается", "Уровень цен остается без изменений", "Уровень цен повышается".
Была написана программа CHCK_MRK (исходной код в приложении 6.4), производящая на основе обучающей выборки классификацию объектов тестовой выборки. Состав обучающей и тестовой выборок приведен в приложении 3.
Таблица 8. Полученные результаты
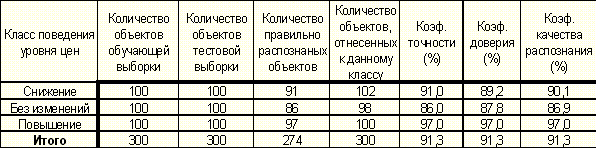
Таким образом, например если программа делает вывод о том, что уровень цен будет повышаться, то вероятность того, что это произойдет в действительности, близка к 0. 97, так как коэффициент доверия для класса "Уровень цен повышается" равен 0. 97, как видно из приведенной выше таблицы.
Пусть, например, сведения о объеме ежедневных продаж коммерческих товаров представлены в виде:
Таблица 9. Пример данных о объеме ежедневных продаж
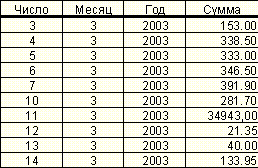
Разбив объем продаж, в процентах к предыдущему рабочему дню, на интервалы-классы можно свести задачу прогнозирования к задаче классификации, в которой требуется на основе сведений о предыдущих днях сделать вывод о том, к какому классу объема продаж, будет относится данный день.
Для начала, построим объектную модель предметной области.
Объект: "Предшествующие продажи". Тип объекта: открытый позиционный контейнер. Элементы контейнера: объекты типа "Продажи за день". Тип объекта "Продажи за день": объект -не-контейнер. Признаки:
Объект "Предшествующие продажи" является контейнером, так как состоит из однотипных объектов "Продажи за день", выступающих как одно целое. Контейнер позиционный, так как дни связаны отношением "следовать" - одни дни предшествуют другим и следуют за третьими. Контейнер открытый, так как в любой из последовательностей дней можно выделить единственный день, являющийся самым первым среди остальных.
Возможны другие варианты построения объектной модели данной предметной области. В качестве альтернативы рассмотрим также объектную модель, в целом подобную предыдущей, единственное отличие - признаки объекта "Продажи за день":
Данная модель позволит обнаружить корреляцию между днем недели и объемом продаж, если она существует.
Классы будут образованы путем деления диапазона от 0 до 200 процентов на одинаковые интервалы. Каждый интервал - один класс объема продаж.
Была написана программа PRF (исходный код в приложении 6.5), позволяющая на основе обучающей выборки относить объекты тестовой выборки к какому-либо из классов объема продаж. Выбор одной из двух вышеописанных объектных моделей производится изменением значения переменной CIdClass на следующие значения: 1 - для модели без учета дня недели; 2 - для модели с учетом дня недели. Состав обучающей и тестовой выборок приведен в приложении 4.
Рассмотрим полученные результаты:
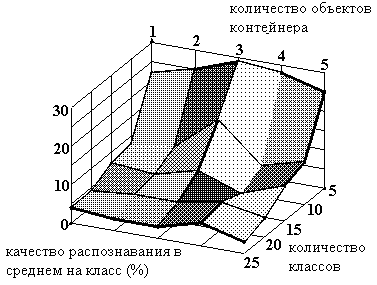
Рисунок 20. Зависимость качества распознавания (модель без учета дня недели) от количества объектов контейнера и количества классов.
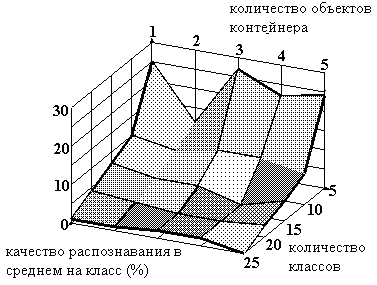
Рисунок 21. Зависимость качества распознавания (модель с учетом дня недели) от количества объектов контейнера и количества классов.
Таблица 10. Зависимость качества распознавания в % (модель без учета дня недели) от количества объектов контейнера и количества классов
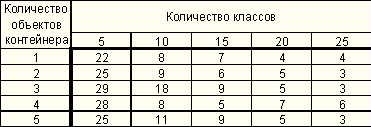
Таблица 11. Зависимость качества распознавания в % (модель с учетом дня недели) от количества объектов контейнера и количества классов
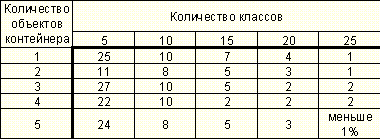
Таким образом, видно что:
корреляция между днем недели и объемом продаж отсутствует или слабо выражена выбранные объектные модели не адекватны, так как не позволяют достичь высокого качества распознавания в данной предметной области
Пусть, например, сведения о объеме ежедневных денежных операциях представлены в виде:
Таблица 12. Пример данных о объеме ежедневных денежных операций
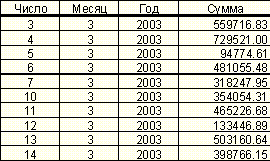
Разбив объем денежных операций, в процентах к предыдущему рабочему дню, на интервалы-классы можно свети задачу прогнозирования к задаче классификации, в которой требуется на основе сведений о предыдущих днях сделать вывод о том, к какому классу объема денежных операций, будет относится данный день.
Для начала, построим объектную модель предметной области.
Объект: "Предшествующие дни". Тип объекта: открытый позиционный контейнер. Элементы контейнера: объекты типа "Объем за день". Тип объекта "Объем за день": объект-не-контейнер. Признаки:
Объект "Предшествующие дни" является контейнером, так как состоит из однотипных объектов "Объем за день", выступающих как одно целое. Контейнер позиционный, так как дни связаны отношением "следовать" - одни дни предшествуют другим и следуют за третьими. Контейнер открытый, так как в любой из последовательностей дней можно выделить единственный день, являющийся самым первым среди остальных.
Возможны другие варианты построения объектной модели данной предметной области. В качестве альтернативы рассмотрим также объектную модель, в целом подобную предыдущей, единственное отличие - признаки объекта "Объем за день":
Данная модель позволит обнаружить корреляцию между днем недели и объемом денежных операций, если она существует.
Классы будут образованы путем деления диапазона от 0 до 200 процентов на одинаковые интервалы. Каждый интервал - один класс объема продаж.
Была написана программа PRF (исходный код в приложении 6.5), позволяющая на основе обучающей выборки относить объекты тестовой выборки к какому-либо из классов объема денежных операций. Выбор одной из двух вышеописанных объектных моделей производится изменением значения переменной CIdClass на следующие значения: 1 - для модели без учета дня недели; 2 - для модели с учетом дня недели. Состав обучающей и тестовой выборок приведен в приложении 5.
Рассмотрим полученные результаты:
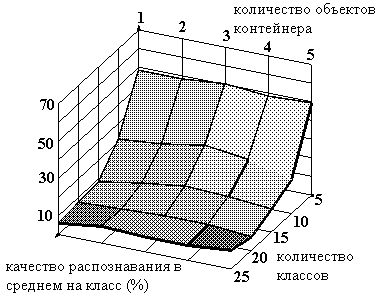
Рисунок 22. Зависимость качества распознавания (модель без учета дня недели) от количества объектов контейнера и количества классов.
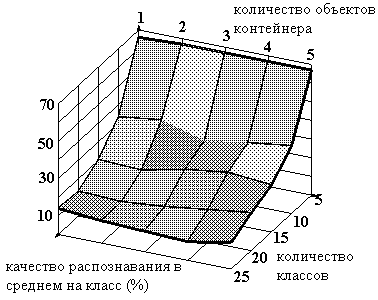
Рисунок 23. Зависимость качества распознавания (модель с учетом дня недели) от количества объектов контейнера и количества классов.
Таблица 13. Зависимость качества распознавания в % (модель без учета дня недели) от количества объектов контейнера и количества классов
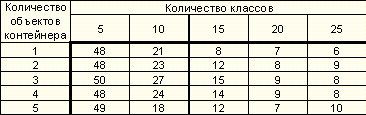
Таблица 14. Зависимость качества распознавания в % (модель с учетом дня недели) от количества объектов контейнера и количества классов
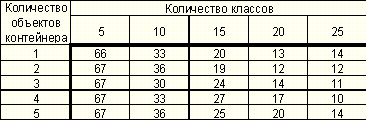
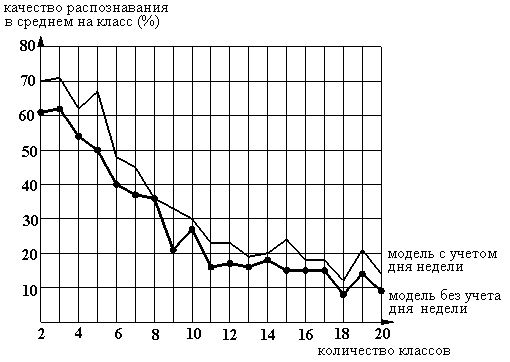
Рисунок 24. Зависимость качества распознавания от количества классов при разных моделях. Количество объектов в контейнера равно трем.
Таблица 15. Зависимость качества распознавания в % от количества классов при разных моделях. Количество объектов в контейнера равно трем.

Таким образом, видно что существует зависимость объема денежных операций от дня недели, следовательно наиболее предпочтительно применение этой модели, учитывающей день недели.
|

 материалы
материалы