|
Один из простейших способов отсортировать массив – сортировка вставками. В обычной жизни мы сталкиваемся с этим
методом при игре в карты. Чтобы отсортировать имеющиеся в вас карты, вы вынимаете карту, сдвигаете оставшиеся карты,
а затем вставляете карту на нужное место. Процесс повторяется до тех пор, пока хоть одна карта находится не на месте.
Как среднее, так и худшее время для этого алгоритма – O(n2). Дальнейшую информацию можно получить в книжке
Кнута [1].
Теория
На рис.2.2(a) мы вынимаем элемент 3. Затем элементы, расположенные выше, сдвигаем вниз – до тех пор, пока не
найдем место, куда нужно вставить 3. Это процесс продолжается на рис. 2.1(b) для числа 1. Наконец, на рис.2.1 (c)
мы завершаем сортировку, поместив 2 на нужное место.
Если длина нашего массива равна n, нам нужно пройтись по n – 1 элементам. Каждый раз нам может понадобиться
сдвинуть n – 1 других элементов. Вот почему этот метод требует довольно-таки много времени.
Сортировка вставками относится к числу методов сортировки по месту. Другими словами, ей не требуется
вспомогательная память, мы сортируем элементы массива, используя только память, занимаемую самим массивом.
Кроме того, она является устойчивой – если среди сортируемых ключей имеются одинаковые, после сортировки они
остаются в исходном порядке.
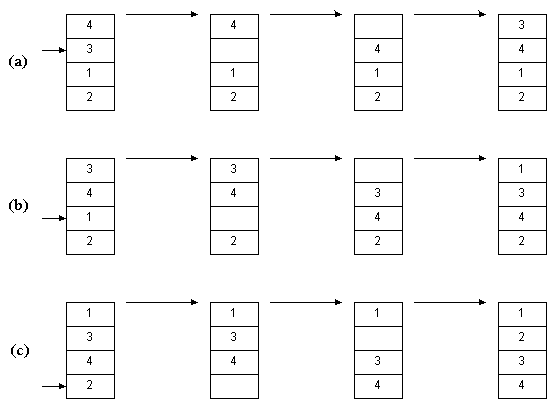 |
Рис. 2.1. Сортировка вставками |
Реализация
Реализацию сортировки вставками на Си вы найдете в разделе 4.1. Оператор typedef T и оператор сравнения
compGT следует изменить так, чтобы они соответствовали данным, хранимым в таблице.
Метод, предложенный Дональдом Л. Шеллом, является неустойчивой сортировкой по месту. Эффективность метода Шелла
объясняется тем, что сдвигаемые элементы быстро попадают на нужные места. Среднее время для сортировки Шелла
равняется O(n1.25), для худшего случая оценкой является O(n1.5). Дальнейшие ссылки см. в
книжке Кнута [1].
Теория
На рис. 2.2(a) был приведен пример сортировки вставками. Мы сначала вынимали 1, затем сдвигали 3 и 5 на одну
позицию вниз, после чего вставляли 1. Таким образом, нам требовались два сдвига. В следующий раз нам требовалось
два сдвига, чтобы вставить на нужное место 2. На весь процесс нам требовалось 2 + 2 + 1 = 5 сдвигов.
На рис. 2.2(b) иллюстрируется сортировка Шелла. Мы начинаем, производя сортировку вставками с шагом 2. Сначала
мы рассматриваем числа 3 и 1: извлекаем 2, сдвигаем 3 на 1 позицию с шагом 2, вставляем 2. Затем повторяем то же
для чисел 5 и 2: извлекаем 2, сдвигаем вниз 5, вставляем 2. И т.д. Закончив сортировку с шагом 2, производим ее с
шагом 1, т.е. выполняем обычную сортировку вставками. Всего при этом нам понадобится 1 + 1+ 1 = 3 сдвига. Таким
образом, использовав вначале шаг, больший 1, мы добились меньшего числа сдвигов.
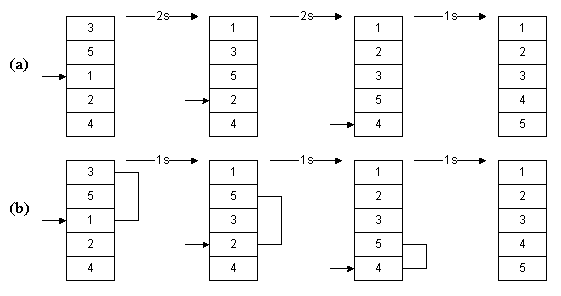 |
Рис. 2.2. Сортировка Шелла |
Можно использовать самые разные схемы выбора шагов. Как правило, сначала мы сортируем массив с большим шагом,
затем уменьшаем шаг и повторяем сортировку. В самом конце сортируем с шагом 1. Хотя этот метод легко объяснить,
его формальный анализ довольно труден. В частности, теоретикам не удалось найти оптимальную схему выбора шагов.
Кнут[1] провел множество экспериментов и следующую формулу выбора шагов (h) для массива длины N:
в последовательности h1 = 1, hs + 1 = 3hs + 1,... взять ht,
если ht + 2 і N.
Вот несколько первых значений h:
h1 = 1
h2 = (3 x 1) + 1 = 4
h3 = (3 x 4) + 1 = 13
h4 = (3 x 13) + 1 = 40
h5 = (3 x 40) + 1 = 121
Чтобы отсортировать массив длиной 100, прежде всего найдем номер s, для которого hs
і 100. Согласно приведенным цифрам, s = 5. Нужное нам значение находится
двумя строчками выше. Таким образом, последовательность шагов при сортировке будет такой: 13-4-1.
Ну, конечно, нам не нужно хранить эту последовательность: очередное значение h находится из
предыдущего по формуле
hs - 1 = | hs / 3 |
Реализация
Реализацию сортировки Шелла на Си вы найдете в разделе 4.2. Оператор typedef T и оператор
сравнения compGT следует изменить так, чтобы они соответствовали данным, хранимым в массиве.
Основная часть алгоритма – сортировка вставками с шагом h.
Хотя идея Шелла значительно улучшает сортировку вставками, резервы еще остаются. Один из наиболее
известных алгоритмов сортировки – быстрая сортировка, предложенная Ч.Хоором. Метод и в самом деле
очень быстр, недаром по-английски его так и величают QuickSort к неудовольствию всех спелл-чекеров
(“...Шишков прости: не знаю, как перевести”).
Этому методу требуется O(n lg n) в среднем и O(n2) в худшем случае. К счастью, если
принять адекватные предосторожности, наихудший случай крайне маловероятен. Быстрый поиск не является
устойчивым. Кроме того, ему требуется стек, т.е. он не является и методом сортировки на месте.
Дальнейшую информацию можно получить в работе Кормена [2].
Теория
Алгоритм разбивает сортируемый массив на разделы, затем рекурсивно сортирует каждый раздел. В
функции Partition (Рис. 2.3) один из элементов массива выбирается в качестве центрального. Ключи,
меньшие центрального следует расположить слева от него, те, которые больше, – справа.
int function Partition (Array A, int Lb, int Ub);
begin
select a pivot from A[Lb]...A[Ub];
reorder A[Lb]...A[Ub] such that:
all values to the left of the pivot are Ј pivot
all values to the right of the pivot are і pivot
return pivot position;
end;
procedure QuickSort (Array A, int Lb, int Ub);
begin
if Lb < Ub then
M = Partition (A, Lb, Ub);
QuickSort (A, Lb, M - 1);
QuickSort (A, M + 1, Ub);
end;
|
На рис. 2.4(a) в качестве центрального выбран элемент 3. Индексы начинают изменяться с концов массива. Индекс
i начинается слева и используется для выбора элементов, которые больше центрального, индекс j начинается справа
и используется для выбора элементов, которые меньше центрального. Эти элементы меняются местами – см. рис. 2.4(b).
Процедура QuickSort рекурсивно сортирует два подмассива, в результате получается массив, представленный на
рис. 2.4(c).
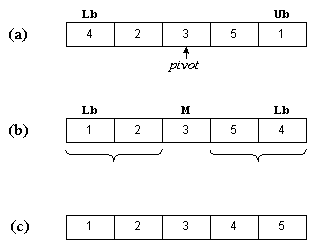 |
Рис. 2.4. Пример работы алгоритма Quicksort |
В процессе сортировки может потребоваться передвинуть центральный элемент. Если нам повезет, выбранный элемент
окажется медианой значений массива, т.е. разделит его пополам. Предположим на минутку, что это и в самом деле так.
Поскольку на каждом шагу мы делим массив пополам, а функция Partition в конце концов просмотрит все n элементов,
время работы алгоритма есть O(n lg n).
В качестве центрального функция Partition может попросту брать первый элемент (A[Lb]). Все остальные элементы
массива мы сравниваем с центральным и передвигаем либо влево от него, либо вправо. Есть, однако, один случай,
который безжалостно разрушает эту прекрасную простоту. Предположим, что наш массив с самого начала отсортирован.
Функция Partition всегда будет получать в качестве центрального минимальный элемент и потому разделит массив
наихудшим способом: в левом разделе окажется один элемент, соответственно, в правом останется Ub – Lb элементов.
Таким образом, каждый рекурсивный вызов процедуры quicksort всего лишь уменьшит длину сортируемого массива на 1.
В результате для выполнения сортировки понадобится n рекурсивных вызовов, что приводит к времени работы алгоритма
порядка O(n2). Один из способов побороть эту проблему – случайно выбирать центральный элемент. Это
сделает наихудший случай чрезвычайно маловероятным.
Реализация
Реализация алгоритма на Си находится в разделе 4.3. Операторы typedef T и compGT следует изменить
так, чтобы они соответствовали данным, хранимым в массиве. По сравнению с основным алгоритмом имеются некоторые
улучшения:
- В качестве центрального в функции partition выбирается элемент, расположенный в середине. Такой
выбор улучшает оценку среднего времени работы, если массив упорядочен лишь частично. Наихудшая для этой
реализации ситуация возникает в случае, когда каждый раз при работе partition. В качестве
центрального выбирается максимальный или минимальный элемент.
- Для коротких массивов вызывается insertSort. Из-за рекурсии и других “накладных расходов” быстрый
поиск оказывается не столь уж быстрым для коротких массивов. Поэтому, если в массиве меньше 12 элементов,
вызывается сортировка вставками. Пороговое значение не критично – оно сильно зависит от качества
генерируемого кода.
- Если последний оператор функции является вызовом этой функции, говорят о хвостовой рекурсии. Ее имеет
смысл заменять на итерации – в этом случае лучше используется стек. Это сделано при втором вызове QuickSort
на рис. 2.3.
- После разбиения сначала сортируется меньший раздел. Это также приводит к лучшему использованию стека,
поскольку короткие разделы сортируются быстрее и им нужен более короткий стек.
В разделе 4.4 вы найдете также qsort – функцию из стандартной библиотеки Си, которая, в соответствии
названием, основана на алгоритме quicksort. Для этой реализации рекурсия была заменена на итерации. В таблице 2.1
приводится время и размер стека, затрачиваемые до и после описанных улучшений.
| count |
Time (ms) |
stacksize |
| before | after | before | after |
| 16 | 103 | 51 | 540 | 28 |
| 256 | 1,630 | 911 | 912 | 112 |
| 4,096 | 34,183 | 20,016 | 1,908 | 168 |
| 65,536 |
658,003 |
470,737 |
2,436 |
252 |
Таблица 2.1. Влияние улучшений на скорость работы и размер стека |
В данном разделе мы сравним описанные алгоритмы сортировки: вставками, Шелла и быструю сортировку. Есть несколько
факторов, влияющих на выбор алгоритма в каждой конкретной ситуации:
- Устойчивость. Напомним, что устойчивая сортировка не меняет взаимного расположения элементов с равными
ключами. Сортировка вставками – единственный из рассмотренных алгоритмов, обладающих этим свойством.
- Память. Сортировке на месте не требуется дополнительная память. Сортировка вставками и Шелла удовлетворяют
этому условию. Быстрой сортировке требуется стек для организации рекурсии. Однако, требуемое этому алгоритму
место можно сильно уменьшить, повозившись с алгоритмом.
- Время. Время, нужное для сортировки наших данных, легко становится астрономическим (см. таблицу 1.1).
Таблица 2.2 позволяет сравнить временные затраты каждого из алгоритмов по количеству исполняемых
операторов.
| Method | statements | erage time | worst-case time |
| insertion sort | 9 | O(n2) | O(n2) |
| shell sort | 17 | O(n1.25) | O(n1.5) |
| quicksort | 21 | O(n lg n) | O(n2) |
Таблица 2.2. Сравнение методов сортировки |
- Время, затраченное каждым из алгоритмов на сортировку случайного набора данных, представлено в таблице 2.3.
| count | insertion | shell | quicksort |
| 16 | 39 ms | 45 ms | 51 ms |
| 256 | 4,969 ms | 1,230 ms | 911 ms |
| 4,096 | 1.315 sec | .033 sec | .020 sec |
| 65,536 |
416.437 sec |
1.254 sec |
.461 sec |
Таблица 2.3. Время сортировки |
|

 материалы
материалы